 Liste de partage de Grorico
Liste de partage de Grorico
Certains ingénieurs de la société Google ont ainsi constaté que le développement logiciel est de plus en plus complexe à organiser, et qu'il prend de plus en plus de temps, tout en étant de moins en moins sûr. Ces ingénieurs ont alors émis l'idée que les outils utilisés jusqu'à présent n'étaient plus adaptés aux défis actuels. Go, le nouveau langage qu'ils ont conçu pour répondre aux défis récents, se veut simple, efficace tout en restant adapté au traitement de problèmes complexes. Ce projet de recherche, qui date de 2007, vient d'être révélé au grand jour mardi 10 novembre dernier.
Une perspective nouvelle
Un pari audacieux

Les trois ingénieurs décident alors de se pencher sur la création d'un langage aussi efficace que les langages compilés habituels, mais aussi agréable à utiliser qu'un langage dynamique comme Python. Ce nouveau langage doit être
- aussi fiable que possible : à la compilation, le programme doit être garanti sans bugs liés aux types ou à une mauvaise gestion de la mémoire. C'est à dire que le programme compilé ne doit pas risquer de planter parce que le programmeur a accidentellement écrit une opération dénuée de sens, comme additionner un entier et une chaîne de caractères, ou tenter d'accéder à une position en mémoire qui n'existe pas. Ces bugs sont parmi les plus répandus, et doivent être découverts par le compilateur si le programmeur ne les aperçoit pas tout seul.
- équipé d'un ramasse-miettes : en C, une mauvaise gestion de la mémoire peut provoquer des plantages ou une consommation inutile. Pour éviter ceci, elle devra donc être confiée à un ramasse-miettes, c'est à dire à un programme qui s'occupe des allocations à la place du programmeur (de façon transparente).
- adapté à la gestion du parallélisme : on veut pouvoir écrire des programmes qui fonctionnent de façon efficace par dessus le réseau, ou en tirant parti de plusieurs processeurs en même temps. Cependant, cela requiert un certain nombre de précautions : que se passe-t-il si plusieurs sous-programmes tentent de modifier en même temps une même donnée ? Ce problème, très actuel, a entraîné la création de nouvelles technologies au cours des dernières années, sous forme de bibliothèques (par exemple Grand Central Dispatch) ou de langages spécialisés (Erlang).
- performant : la rapidité d'exécution des programmes écrits avec ce langage doit être comparable à celle du C. Bien que cet objectif dépende davantage moins du langage lui-même que de son implémentation (c'est à dire son compilateur, etc.), certains choix doivent être faits pour l'atteindre. Notamment, le langage doit être statique, c'est à dire que les types des données manipulées doivent être connus à la compilation, et pas à l'exécution comme dans le cas de langages dynamiques.
- simple, tant dans sa conception qu'à l'utilisation : les langages modernes sont de plus en plus complexes (car ils possèdent de plus en plus de caractéristiques), et manquent toutefois de fonctionnalités parfois jugées essentielles. Ils disposent alors de bibliothèques pour pallier ces manques, et ces dernières complexifient encore le rôle du développeur. Un langage moderne doit donc se débarasser de cette fâcheuse habitude. De plus, la syntaxe devra être simple, concise, mais lisible et régulière.
- capable de compiler le plus rapidement possible.
Une équipe de choc

dessinée par la femme de Rob Pike.
Durant l'année 2008, le langage Go est pratiquement conçu, et une première implémentation est mise en oeuvre. D'autres ingénieurs rejoignent le projet, et l'équipe se concentre alors sur l'optimisation du langage et de sa compilation. Deux compilateurs sont développés : 6g, nommé ainsi d'après la tradition des compilateurs du système Plan 9, ainsi que gccgo, basé sur le compilateur GCC. Les deux implémentations sont pour l'instant maintenues, la première en raison d'une plus grande rapidité, la seconde pour son efficacité accrue. Pour l'heure, il n'existe pas de compilateur tournant sous Windows : l'équipe déplore une trop faible quantité de programmeurs, mais espère que l'ouverture totale du langage et de ses implémentations (qui sont libres) attirera des contributeurs.
Le langage Go
Un descendant du C revu et amélioré.
À l'instar du C, Go est un langage impératif : un programme se compose comme une suite d'instructions qui ont un ordre. Go est clairement un héritier du C, dont il reprend une partie de la syntaxe. Cependant, celle-ci a été revue afin d'être à la fois plus claire et plus concise (moins de choses à écrire). Voici le code d'un programme helloworld.go retournant "Hello, world ; salut les Zéros" comme résultat :
Code : Python
1 2 3 4 5 6 7 | package main import fmt "fmt" // Contient des fonctions de formatage func main() { fmt.Printf("Hello, world ; salut les Zéros\n"); } |
Un certain nombre de différences sautent immédiatement aux yeux. Vous pouvez immédiatement voir que ce programme fait partie du paquet nommé "main", qu'il utilise le paquet "fmt" pour le formatage. Au sein de la fonction main (qui sera appelée au lancement du programme), vous retrouvez le printf du C, mais actualisé, puisqu'il fait partie du paquet "fmt". Les paquets servent à organiser les dépendances, en les rendant moins chaotiques qu'en C. Notez que les chaînes de caractères de Go sont prévues pour gérer l'encodage UTF-8.

D'autres ambiguités ont été levées : le piège des opérateurs ++ et -- a été levé, puisqu'ils sont désormais considérés comme des instructions et plus comme faisant partie d'une expression. Le but est d'enlever les erreurs et indéterminations en empêchant d'écrire des choses comme p[i] = q[++i]. Les pointeurs du C sont également présents, mais leur utilisation a été restreinte, puisque notamment l'arithmétique de pointeurs n'est plus possible : les créateurs du langage soutiennent que ce type d'opérations n'est plus nécessaire aujourd'hui, et qu'il complique l'utilisation du ramasse-miettes.
Le site du langage présente notamment une page dédiée aux différences avec le langage C++, dont certains points valent aussi pour le C.
Un système de types simple mais moderne.
Go veut privilégier la concision, en permettant au programmeur de ne rien écrire d'inutile. Dans la conférence de présentation du langage, Rob Pike donne notamment l'exemple suivant foo.Foo *myFoo = new foo.Foo(foo.FOO_INIT) de code que Go veut éviter. Ainsi, si un programmeur Go doit écrire var t0 *T = new(T); , ce qui est parfaitement valide mais inutilement redondant, il peut l'abréger en t1 := new(T); . L'opérateur := dénote une affectation initiale, comme on le ferait dans le langage Io. Cependant, ça n'est pas parce que le type de t1 n'est pas donné explicitement qu'il est inconnu à la compilation : le compilateur déduit automatiquement ce type via un mécanisme que l'on appelle "inférence de types", comme dans les langages Haskell ou OCaml.
Pour atteindre la concision et l'efficacité, Go présente un système de types proche de celui du langage Python, appelé "duck typing". Ce nom original représente un principe simple : si un objet a un bec de canard, et qu'il cancanne comme un canard, alors on peut l'utiliser comme un canard. Plus sérieusement, en Python, on ne se préoccupe pas du type exact des objets, mais des opérations supportées. Cela permet par exemple d'utiliser la même fonction len sur des listes ou des chaînes de caractères pour en mesurer la longueur. Cela permet aussi au programmeur d'implémenter l'opération correspondant à la fonction len sur ses propres objets pour que ceux-ci puissent également être utilisés avec la fonction.
Cependant, Python est flexible au détriment de la sécurité : si vous utilisez une fonction cancanner sur un objet qui ne cancanne pas, l'erreur ne sera détectée que pendant l'exécution de votre programme, et pas pendant la compilation. Cela pose problème car pour vérifier votre programme, vous devez alors le tester dans de multiples situations - ce qui ne garantit même pas son fonctionnement à 100 %. Go va donc plus loin, en proposant de vérifier à la compilation les opérations supportées par vos objets. Ceci est réalisé par un mécanisme d'interfaces, comme dans les langages Java ou Objective-C (où ils sont appelés "protocoles").
Par exemple, la fonction Printf sait afficher les objets répondant à l'interface Stringer, c'est à dire ceux équipés d'une méthode String. Voici un exemple de définition d'une interface, puis d'un nouveau type respectant cette interface :
Code : Python
1 2 3 4 5 6 7 8 9 | type Stringer interface { String() string } type testType struct { a int; b string } func (t *testType) String() string { // Ceci est bien une méthode du type testType return fmt.Sprint(t.a) + " " + t.b // Le + peut servir à concaténer des chaînes } |
Ici, testType est une structure comportant un entier a et une chaîne b, et on définit comment afficher les objets de type testType. Lorsque Printf voudra afficher un de ces objets, il appellera la méthode String et affichera le résultat. Cependant, notez bien que rien dans ce code ne laisse supposer la présence de classes comme dans la majorité des langages objets : les concepteurs de Go jugent en effet que ce concept n'est pas nécessaire à la programmation orientée objet, ou à la programmation tout court. Notamment, ils jugent l'introduction de hiérarchie entre les types (par exemple par héritage) comme étant artificielle et inadaptée. Le système d'interfaces permet quant à lui un polymorphisme jugé simple et naturel.
Enfin, les types de base proposés par Go sont grossièrement les mêmes types de base que ceux de Python : le programmeur aura rarement à se préoccuper de la différence entre int et long , ou float et double , mais pourra se contenter de distinguer int et float (entier ou décimal). De plus, des types plus ou moins élaborés comme les chaînes, les tableaux, mais aussi les "slices" (sous-tableaux utilisant des références) et les "maps" (tableaux associatifs) sont fournis par défaut. Enfin, les fonctions peuvent être très naturellement manipulées, notamment passées en argument à d'autres fonctions.
Les outils du parallélisme
Go est un langage dit "concurrent", c'est à dire conçu pour faire tourner plusieurs tâches plus ou moins indépentantes en même temps, et pour les faire communiquer de façon naturelle. Pour cela, Go implémente le paradigme CSP, conçu par Charles Hoare en 1978. Ce paradigme conçoit les processus comme tournant indépendamment les uns des autres, avec pour seul moyen de communication des messages qu'ils s'envoient les uns aux autres (à condition de connaître l'adresse du destinataire).
Cette façon de faire était déjà implémentée par certains langages, notamment Erlang, qui a connu un certain succès dans le domaine de l'écriture de serveurs (notamment ejabberd) supportant facilement des milliers de connexions simultanées, mais dont la puissance de calcul était en revanche très limitée. Go pourrait donc proposer une alternative plus adaptée aux calculs lourds dans ce domaine.
De même qu'en Erlang, les processus utilisés pour la programmation concurrente sont des "processus légers", dont l'exécution peut être lancée facilement de façon à ce que des milliers de processus s'exécutent simultanément. On les appelle "goroutines" en Go, afin de les distinguer d'éventuels processus systèmes, plus lourds et dédiés à une utilisaiton différente. Même si ce côté n'a pour l'instant été que peu évoqué pour Go, ils peuvent alors être répartis sur plusieurs cœurs, voire sur plusieurs ordinateurs, sans que cela perturbe le déroulement du programme.
Dans l'exemple suivant, la fonction processus va être lancée dans deux nouveaux processus, via l'instruction go :
Code : Python
1 2 3 4 5 6 7 8 | func server(i int) { for { // La boucle for seule équivaut au while du C print(i); sys.sleep(10) } } go server(1); go server(2); |
La communication entre processus se fait simplement à l'aide de l'opérateur <-. Des exemples peuvent être trouvés dans la documentation du langage.
Quel avenir pour le langage ?
Malgré des caractéristiques alléchantes, il est encore trop tôt pour dire si Go réussira à percer. Les langages qu'il veut détrôner semblent multiples (C++ ? Java ? Python ?) et sont tous bien plus matures que lui. D'ailleurs, Go n'est pour l'instant guère plus qu'un intéressant projet de langage, encore susceptible d'évoluer. De plus, des langages comparables existaient déjà ces dernières années. Par exemple, le langage D prétendait lui aussi être plus moderne que C++, et être capable de remplacer ce langage. Pour l'instant, rien de tel ne s'est produit. De même, OCaml, développé par l'INRIA, est fiable, performant, et en certains points comparables à Go - mais il n'a pas vraiment non plus connu de succès dans le milieu industriel.
Ainsi, le futur de Go est incertain. Même son nom est susceptible d'être modifié : il existe en effet déjà un langage concurrent nommé Go!, ce qui ressemble beaucoup trop au langage de Google pour son auteur. Cependant, pour certains, le milieu de la programmation a bien toléré pendant des années que des langages s'appellent C, C++ et C#...
Pour les passionnés, Go représente en tout cas au moins un jouet intéressant, et éventuellement un langage adapté pour l'apprentissage de la programmation concurrente. Google n'a pas annoncé pour l'instant de projet majeur écrit en Go, même si le serveur du site officiel du langage, Golang.org est écrit en Go. Il sera donc également intéressant de voir dans quelle mesure Go est adopté par ses propres géniteurs, et notamment d'étudier s'il remplace Python, très utilisé par Google en interne.
Quelques liens :
- Comment démarrer avec Go, pour les utilisateurs de systèmes Unix ;
- La conférence de présentation de Go sur Youtube : Rob Pike présente Go aux GoogleTech days. Des fichiers PDF sont également disponibles ;
- Un tutoriel en anglais sur Go.
Google travaille sur une nouvelle version de son navigateur Google Chrome, et ils se sont attaqués sur une partie très primaire du navigateur : la transmission de données entre le client et le serveur. Le but de l’opération est clair : réduire le temps de latence du serveur dans une requête de type HTTP. Sauf que la requête ne sera plus du célèbre protocole HTTP, mais d’un nouveau protocole créé par Google : SPDY. Soit, le SPeeDY, pour ceux qui n’ont toujours pas compris, dans notre langue de Molière cela donne : « Rapide ». Les premiers résultats sont très encourageants, car ils notent une diminution de 55 % du temps de latence par rapport au protocole HTTP.
 SPDY n’est pas là pour vraiment remplacer HTTP, mais seulement à termes une partie liée à certains aspects comme l’échange de données. Google a choisi un développement open-source sur ce type de projet, pour permettre une accessibilité plus importante.
SPDY n’est pas là pour vraiment remplacer HTTP, mais seulement à termes une partie liée à certains aspects comme l’échange de données. Google a choisi un développement open-source sur ce type de projet, pour permettre une accessibilité plus importante.
Quelle conséquence pour Android ? Une navigation bien sûr plus rapide, mais cela reste à prouver et vérifier.
Pour en apprendre plus sur SPDY, vous pouvez lire le livre blanc dédié à ce nouveau protocole (si vous comprenez tout ce charabias : TCP, RTT…).
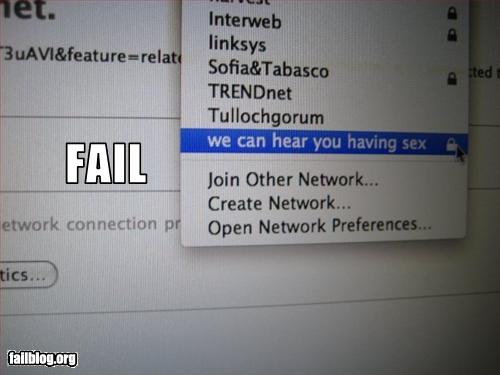
Il y a parfois des choses que l'on aimerait dire à ses voisins sans aller frapper à leur porte, et sans qu'ils sachent qui l'on est. Pour cela, changer le nom de son réseau WiFi (SSID) peut être une excellente méthode, comme le montre cette image de Failblog qui se passe de commentaire :
 Est-ce uniquement par leur licence qu’un noyau Linux et une encyclopédie Wikipédia sont identifiés comme étant libres ?
Est-ce uniquement par leur licence qu’un noyau Linux et une encyclopédie Wikipédia sont identifiés comme étant libres ?
Juridiquement parlant oui, mais s’en tenir là serait passer à côté du modèle collaboratif particulier que ce sont donnés ces deux fleurons de la culture libre pour développer leur projet.
Conséquence de la licence, c’est aussi voire surtout la puissance de ce modèle qui caractérise le Libre. Et ce modèle commence à se diffuser un peu partout dans la société…
Les mathématiques sont « libres » depuis la nuit des temps (enfin depuis que les pythagoriciens ont cessé de se cacher, pour être plus précis)[1]. Chacun est libre des les étudier, les copier et les améliorer en étant fortement encouragé à rendre évidemment publiques ces améliorations, dans la plus pure tradition universitaire.
C’est absurde, mais si il fallait a posteriori leur accoler une licence issue de la culture libre, ce pourrait être la plus simple des Creative Commons, la CC-By, puisque cette notion de paternité est très importante dans un monde scientifique avant tout motivé par la reconnaissance des pairs et la place laissée dans l’Histoire de leur champ disciplinaire.
On retrouve d’ailleurs souvent les crédits et les hommages dans les noms que l’on donne aux résultats. On parlera ainsi de la preuve selon Euclide du théorème de Thalès.
Les mathématiques seraient donc « libres », les professeurs également (enfin surtout en France dans le secondaire avec Sésamath), mais quid des mathématiciens eux-même et de leurs pratiques ? Et si ils s’organisaient à la manière d’un projet de développement d’un logiciel libre pour chercher et éventuellement trouver ensemble des résultats importants ?
Entendons-nous bien. Les mathématiciens ne vivent bien entendu pas dans une tour d’ivoire. Ils sont habitués à travailler et échanger ensemble au sein d’un laboratoire, lors d’un séminaire… et évidemment sur Internet. Mais l’aventure intellectuelle et collective du « Projet Polymath » que nous avons choisi de vous narrer ci-dessous est un peu différente, en ce sens que ses auteurs eux-mêmes la définissent comme une expérience « open source ».
Ne vous arrêtez surtout pas à la complexité mathématique de ce qu’ils cherchent à accomplir (à savoir une « meilleure » preuve d’un théorème déjà démontré !), c’est totalement secondaire ici. Ce qui nous intéresse en revanche c’est comment ils y sont arrivés (désolé d’avoir vendu la mèche) et les enseignements qu’ils en tirent pour l’avenir.
Parce qu’il se pourrait que cet mode opératoire, original et efficient, fasse rapidement des émules, et ce bien au delà des mathématiques.
Remarque : C’est le terme « open source » qui a été choisi tout du long par les auteurs et non « free software ». Contrairement au domaine logiciel, il ne s’agit pas d’un choix ou d’un parti pris mais tout simplement d’une question de sens : « open source mathematics » étant largement plus signifiant que « free software mathematics » !
Mathématiques massivement collaboratives
Massively collaborative mathematics
Timothy Gowers[2] et Michael Nielsen[3] - 24 octobre 2009 - Nature.com (Opinion)
(Traduction Framalang : Olivier et Goofy)
Le « Projet Polymath » est la preuve que l’union de nombreux cerveaux peut résoudre des problèmes mathématiques complexes. Timothy Gowers et Michael Nielsen nous livrent leurs réflexions sur ce qu’ils ont appris des sciences open source.
Le 27 janvier 2009, l’un d’entre nous, Gowers, a lancé une expérience inhabituelle par l’intermédiaire de son blog (NdT : avec ce billet Is massively collaborative mathematics possible?). Le Projet Polymath s’était fixé un but scientifique conventionnel : s’attaquer à un problème mathématique irrésolu. Mais son but plus ambitieux était d’innover dans la recherche en mathématiques. Reprenant l’idée des communauté open source comme Linux et Wikipédia, le projet s’appuyait sur des blogs et des wikis pour canaliser une collaboration complètement ouverte. Libre à tout un chacun d’en suivre la progression et s’il le désire d’apporter sa contribution. Les blogs et wikis étaient en quelque sorte une mémoire à court terme collective, un brainstorming ouvert à grande échelle dédié à l’amélioration des idées.
Le résultat de la collaboration dépassa de loin les espérances de Gowers, offrant une belle illustration de ce que nous pensons être une dynamique formidable pour les découvertes scientifiques : la collaboration de nombreux cerveaux connectés par Internet.
Le Projet Polymath visait à trouver une preuve élémentaire d’un cas particulier du théorème de Hales-Jewett sur la densité (NdT : DHJ pour Density Hales-Jewett), théorème central de l’analyse combinatoire, une branche des mathématiques qui étudie les structures discrètes (voir Morpion à plusieurs dimensions). Ce théorème avait déjà été démontré, mais les mathématiciens ne se contentent pas toujours d’un seul chemin. De nouvelles preuves peuvent déterminantes pour une meilleure compréhension du théorème. Trouver une nouvelle démonstration du théorème DHJ était important pour deux raisons. Tout d’abord il fait partie d’un ensemble de résultats fondamentaux possédant plusieurs démonstrations, alors que le théorème DHJ n’en avait jusqu’alors connu qu’une seule, longue, complexe, et très technique. Seul un élan de nouvelles idées pouvait amener à une preuve plus simple, s’appuyant sur des concepts de base plutôt que sur des techniques compliquées. Ensuite, du théorème DHJ découle un autre théorème important, le théorème de Szemerédi. La découverte de nouvelles preuves de ce théorème a conduit à de grandes avancées au cours de la dernière décennie, on pouvait donc raisonnablement s’attendre à ce qu’un même phénomène accompagne la découverte d’une nouvelle démonstration du théorème DHJ.
À l’origine du projet on retrouve Gowers. Il publia une description du problème, indiqua quelques ressources et établit une liste préliminaire de règles régissant la collaboration. Grâce à ces règles, les échanges sont restés polis et respectueux, elles encourageaient les participants à proposer une et une seule idée par commentaire, même sans la développer complètement. Ces règles stimulaient ainsi les contributions et aidaient à conserver le caractère informel de la discussion.
Mettre le projet sur les bons rails
La discussion collaborative a vraiment commencé le 1er février, doucement : il a fallu attendre plus de 7 heures avant que Jozsef Solymosi, un mathématicien de l’Université de la Colombie Britannique à Vancouver, fasse le premier commentaire. Quinze minutes après, un nouveau commentaire était posté par Jason Dyer, enseignant dans un lycée de l’Arizona. Trois minutes après, c’est Terence Tao (lauréat de la médaille Fields, la plus haute distinction en mathématiques), de l’Université de California à Los Angeles, qui écrivit son commentaire.
Au cours des 37 jours qui suivirent, ce sont pas moins de 27 personnes qui ont apporté leur contribution au travers d’environ 800 messages, pour un total de 170 000 mots. Personne n’a été spécialement invité à participer : la discussion était ouverte à tout le monde, des doctorants aux experts mathématiciens. Nielsen a mis en place un wiki pour mettre en avant les contributions importantes apparues dans les commentaires du blog. Au moins 16 autres blogs ont parlé du projet, il s’est hissé à la première page de l’agrégateur Slashdot technology et a donné naissance à un projet assez proche sur le blog de Tao.
Tout s’est déroulé sans accroc : pas de « trolls » (ces adeptes des posts non constructifs, voire malveillants), ni de commentaires bien intentionnés mais complètement inutiles (on peut malgré tout signaler que le wiki a été spammé). Le rôle de modérateur pris par Gowers se résumait essentiellement à corriger les fautes.
Le projet progressa bien plus rapidement qu’attendu. Le 10 mars, Gowers annonça qu’il était assez sûr que les participants au projet Polymath avaient découvert une preuve élémentaire d’un cas particulier du théorème DHJ et, qu’étonnamment (compte tenu des expériences avec des problèmes similaires), cette preuve pouvait être généralisée assez facilement pour prouver le théorème entier. La rédaction d’un article décrivant cette preuve est entreprise, ainsi que celle d’un second papier décrivant des résultats liés. De plus, alors que le projet était encore actif, Tim Austin, doctorant à l’Université de Californie, Los Angeles, publia une autre preuve (non élémentaire celle-ci) du théorème DHJ en s’appuyant largement sur les idées développées dans le projet Polymath.
Les archives du projet Polymath constituent une ressource exceptionnelle pour les étudiants en mathématiques, les historiens et autres philosophes des sciences. Pour la première fois, on peut suivre le cheminement intellectuel complet à l’origine d’un résultat mathématique sérieux. On y voit les idées naître, grandir, changer, s’améliorer ou être abandonnées, et on y découvre que la progression de la compréhension ne se fait pas nécessairement par un unique pas de géant, mais plutôt par le regroupement et le raffinement de plusieurs petites idées.
C’est un témoignage direct de la persévérance dont il faut faire preuve pour résoudre un problème complexe, pour progresser malgré les incertitudes et on réalise que même les meilleurs mathématiciens peuvent faire des erreurs simples et s’entêter à creuser une idée vouée à l’échec. Il y a des hauts et des bas et on ressent une vraie tension à mesure que les participants s’approchent d’une solution. Les archives d’un projet mathématique peuvent se lire comme un thriller, qui l’eût cru ?
Des implications plus larges
Le projet Polymath ne ressemble pas aux collaborations à grande échelle traditionnelles, comme on peut en trouver dans l’industrie ou dans les sciences. En général, ces organisations sont divisées hiérarchiquement. Le projet Polymath était complètement ouvert, chacun était libre d’apporter sa pierre à l’édifice… n’importe quelle pierre. La variété des points de vue a parfois apporté des résultats inattendus.
Se pose alors la question de la paternité : difficile de décréter une règle de paternité stricte sans heurt ou sans décourager des contributeurs potentiels. Quel crédit accorder aux contributeurs apportant uniquement une idée perspicace, ou à un contributeur très actif mais peu perspicace ? Le projet a adopté une solution provisoire : il signe ses articles du pseudonyme « DHJ Polymath » suivi d’un lien vers les archives (NdT : cf cette première publication ainsi signée A new proof of the density Hales-Jewett theorem). Grâce à la collaboration ouverte privilégiée par le projet Polymath, on sait exactement qui a fait quoi. Au besoin, une lettre de recommandation peut isoler les contributions d’un membre du projet en particulier, comme c’est déjà le cas en physique des particules où il est courant de voir des articles avec des centaines d’auteurs.
Se pose aussi le problème de la conservation. Les archives principales du projet Polymath sont dispersées sur deux blogs (1 et 2) et un wiki, le rendant très dépendant de la disponibilité de ces sites. En 2007, la bibliothèque du Congrès américain a initié un programme de conservation des blogs tenus par les professionnels du droit. De la même manière, mais à plus grande échelle, un programme similaire est nécessaire pour conserver les blogs et wikis de recherche.
D’autres projets, ayant vu le jour depuis, permettront d’en apprendre plus sur le fonctionnement des mathématiques collaboratives. Il est en particulier crucial de savoir si ce genre de projet peut être élargi à plus de contributeurs. Bien qu’il ait rassemblé plus de participants qu’une collaboration classique en mathématiques, le projet Polymath n’est pas devenu la collaboration massive que ses créateurs espéraient. Ceux qui y ont participé s’accordent sur le fait que pour grandir, il faudrait que le projet adapte sa manière de procéder. La narration linéaire du blog posait, entre autre, problème aux nouveaux arrivants. Difficile pour eux, parmi la masse d’informations déjà publiées, d’identifier où leur aide serait la plus précieuse. Il y avait également le risque qu’ils aient loupé un « épisode » et que leur apport soit redondant.
Les projets de logiciels libres utilisent des logiciels de suivi de version pour organiser le développement autour des « problèmes », des rapports de bogues ou des demandes de fonctionnalités en général. Ainsi, les nouveaux arrivants ont une vision claire de l’état du projet, ils peuvent concentrer leurs efforts sur un « problème » particulier. De même, la discussion est séparée en modules. Les futurs projets Polymath pourraient s’en inspirer.
Bientôt, les sciences ouvertes
L’idée derrière le projet Polymath est potentiellement applicable à tous les défis scientifiques, mêmes les plus importants comme ceux pour lesquels le Clay Mathematics Institute de Cambridge, Massachussets offre un prix d’un million de dollars. Même si certaines personnes souhaiteront toujours garder tout le mérite pour elles-mêmes et être pour ainsi dire refroidies par l’aspect collaboratif, d’autres au contraire pourraient y voir une excellente opportunité d’être associés à la résolution de l’un de ces problèmes.
Dans d’autres disciplines, l’approche open source ne gagne que très lentement du terrain. Un domaine s’y est ouvert avec succès : la biologie synthétique. Les informations ADN d’organismes vivants sont enregistrées numériquement et envoyées à un dépôt en ligne, comme celui du MIT Registry of Standard Biological Parts. D’autres groupes peuvent utiliser ces informations dans leur laboratoire et, s’ils le souhaitent, reverser leurs améliorations au dépôt. qui compte actuellement plus de 3 200 contributions, apportées par plus de 100 entités différentes. Les découvertes qui en découlent ont fait l’objet de nombreux articles comme par exemple Targeted Development of Registries of Biological Parts. La biologie open source et les mathématiques open source montrent comment la science peut progresser grâce aux diverses contributions apportées par des gens aux compétences variées.
On pourrait, de la même manière, employer ces techniques open source dans d’autres domaines, telle la physique et l’informatique théoriques, où les données brutes contiennent de nombreuses informations et peuvent être partagées librement en ligne. Appliquer les techniques open source aux travaux pratiques est plus délicat, les conditions expérimentales étant difficilement reproductibles. Quoiqu’il en soit, le partage libre des données expérimentales permet néanmoins leur analyse libre. Adopter ces techniques open source à grande échelle ne sera possible que grâce à un changement profond des mentalités en science et au développement de nouveaux outils en ligne. Nous croyons à un fort développement de la collaboration de masse dans de nombreux domaine des sciences, et que cette collaboration massive repoussera les limites de nos capacités à résoudre des problèmes.
Notes
[1] Crédit photo : Robynejay (Creative Commons By-Sa)
[2] Timothy Gowers appartient au Departement of Pure Mathematics and Mathematical Statistics de l’Université de Cambridge, Wilberforce Road, Cambridge CB3 0WB, UK et il est Royal Society 2010 Anniversary Research Professor.
[3] Michael Nielsen est écrivain et physicien, il habite à Toronto et travaille sur un livre sur le futur de la science.
Ce n'est pas nécessairement la première chose à laquelle on pense lorsqu'on s'inscrit sur un réseau social, mais il arrivera un moment où l'internaute passe l'arme à gauche. Or, quid de tous ses profils sur Internet ? Quid de ses mises à jour ? En ce qui concerne Facebook, le profil ne sera ni supprimé, ni désactivé, mais sera rangé dans une catégorie spéciale.
[Lire la suite]