 Liste de partage de Grorico
Liste de partage de Grorico

Le reproche le plus fréquemment adressé à Google concerne bien évidemment les données utilisateurs. Nombreux sont ceux à voir en la firme un nouvel antéchrist numérique profitant de la naïveté des internautes pour épier leur vie privée. Oui, comme quoi la réussite ne paie jamais vraiment. Cela dit, le géant américain semble bien décidé à renverser la vapeur, comme en témoigne son Google Data Liberation…

La dématérialisation, c’est l’avenir qu’ils disent… Et il faut avouer que le machin est plutôt pratique. Ceux qui connaissent bien le web le savent, aujourd’hui il est possible de s’affranchir de la plupart des logiciels qui étaient encore incontournables il y a cinq ans de cela. Oui et c’est un bon point, même s’il soulève quelques questions plutôt perturbantes et même s’il a tendance à rendre les gens un tantinet paranoïaques.
Sur la question, c’est souvent Google que l’on pointe du doigt. Il faut dire aussi que la firme américaine est de plus en plus présente sur le web et qu’elle compte en plus un grand nombre d’utilisateurs. Aujourd’hui, de nombreux internautes gèrent leurs mails avec Gmail, leur calendrier avec Google Agenda ou encore leurs documents avec Google Documents et certains s’en inquiètent énormément.
Pour leur répondre, Google a décidé de prendre les devants en lançant Google Data Liberation. Ce service se présente un peu comme un wiki dédié à tous les services de la firme. Pour chacun d’entre eux, on peut donc trouver des procédures complètes nous permettant, par exemple, de quitter Gmail pour un autre fournisseur ou exporter l’intégralité de son calendrier Google Agenda.
Alors bien entendu, il y aura toujours des gens pour critiquer, mais le fait est que Google est sans doute le premier à proposer ce type de services. Et pourtant, des concurrents, il en a un sacré paquet, hein…
Où pourquoi ne pas par exemple ajouter sa mère comme ami sur Facebook, ou détailler sa vie dans les moindres recoins quand on est une fille…
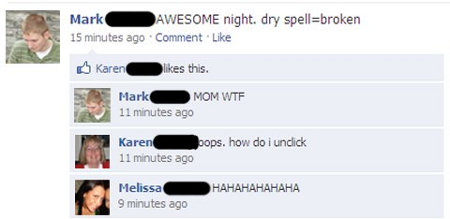
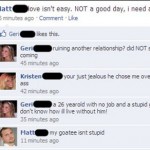
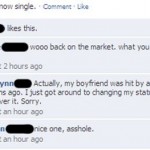
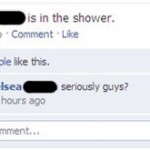
via geekologie
Partager :Tags:Facebook, FAIL, Fun, Sur le web
Sur le même sujet :
- Perdre son job “grâce” à Facebook… (66)
- Ne pas se vanter sur Facebook… (35)
- Encore un cas de FAIL sur Facebook… (26)
- Web Site Story (12)
- Walt Mossberg façon Muppet Show… (2)

Voilà 20 ans que le web existe et presque 10 ans que le HTML n’a pas évolué et propose toujours la même structure et les mêmes balises. 10 ans c’est beaucoup, c’est la moitié de la “vie” du web. 10 ans c’est beaucoup, surtout lorsque l’on constate les révolutions qui ont eu lieu dans les usages du web ces 5 dernières années (partage de vidéos, réseaux sociaux, infos en temps réel…). Pas étonnant que des technologies propriétaires (Flash) se soient imposées (notamment sur la vidéo et les RIA) et que d’autres s’installent tranquillement pour combler un manque (notamment Google Gears pour l’accès hors ligne).
Bref, il était temps que le marché se réveille et c’est (presque) chose faite avec l’arrivée à maturation de HTML 5 et CSS 3. Pour faire simple, disons que nous avons franchi le point de bascule et que la route qui mène à une adoption de ces nouveaux standards n’est plus si longue. Pourquoi est-ce important de se soucier de ça ? Tout simplement parce que ces nouvelles spécifications vont changer beaucoup de choses dans la façon de concevoir et d’exploiter les interfaces web, des changements qui vont fortement impacter les différents métiers de la profession.
Autant vous prévenir tout de suite : les explications qui vont suivre sont une tentative de l’auteur de résumer et vulgariser un foutoir pas possible (qui provoquent d’innombrables querelles d’experts depuis des années : HTML 5 is a mess. Now what?) sans pour autant prendre partie car de toute façon les choses semblent visiblement s’améliorer. Je ne donne que mon interprétation, vous êtes libre de proposer la votre.
Commençons donc par nous intéresser à cette nouvelle version de HTML et pourquoi s’est-elle imposée face à XHTML (pour une explication plus détaillée c’est ici : XHTML 2 vs. HTML 5, et là : Misunderstanding Markup: XHTML 2/HTML 5 Comic Strip).
HTML vs. XHTML
Au commencement il y avait donc le HTML 4 dont les spécifications ont été publiées en 1997. Une légère évolution a été publiée en 1999 avec le HTML 4.01. Puis le W3C a décidé de miser sur le langage XML (plus sophistiqué et surtout extensible) en proposant une reformulation du HTML avec les balises du XML, à savoir le XHTML 1.0. Tout l’intérêt de cette reformulation est de pouvoir marier la simplicité du HTML avec la puissance du XML (et ses nombreuses possibilités d’évolution).
Sur cette lancée, le W3C a alors lancé le chantier XHTML 2 pour faire une réécriture complète des spécifications et poser de nouvelles bases pour un langage plus puissant, plus robuste, plus évolutif… bref, un langage qui propulserait le web dans une autre dimension sans toutefois assurer de rétro-compatibilité. Hé oui… car il faut bien faire table rase pour pouvoir redémarrer sur des bases saines. Et c’est bien là le problème : ne pas assurer la rétro-compatibilité était inacceptable pour l’industrie (et notamment les éditeurs de navigateurs) qui ont alors décidé de lancer des travaux indépendant sous l’aile du WHATWG (Web Hypertext Application Technology Working Group). Ce groupe de travail a commencé à travailler sur les spécifications des Web Applications.
Après un bras de fer de plusieurs années (et un constat d’échec pour l’équipe de travail sur les spécifications XHTML 2), le W3C a fini par réintroduire les spécifications du WHATWG et de créer un groupe de travail officiel sur le HTML 5 tout en abandonnant l’autre chantier (RIP XHTML 2).
Par élimination il ne reste donc plus qu’un seul prétendant au titre de remplaçant du HTML 4, d’autant plus qu’il a reçu le soutien de qui vous savez (Google Bets Big on HTML 5). Nous sommes donc semble-t-il arriver à un consensus de l’industrie sur des spécifications qui ne sont pas aussi ambitieuses que celles d’XHTML 2 mais qui ont l’énorme mérite de faire avancer les choses (souvenez vous qu’il n’y a pas eu d’évolution en 12 ans).
Qu’est-ce qui va changer avec HTML 5 ?
Pour faire simple disons qu’avec HTML 5 nous allons quitter l’ère du web des documents pour enter dans celle du web des applications. L’ambition de cette nouvelle itération est donc de supprimer les balises obsolètes, d’en remplacer certaines et d’en introduire de nouvelles afin de donner une structure sémantique plus cohérente aux pages web.
De nouvelles API vont ainsi standardiser un certain nombre d’interactions :
- L’accès hors ligne et le stockage sur le disque dur (pour une exploitation en mode déconnecté) ;
- L’édition en ligne, le drag&drop ;
- L’accès à l’historique de navigation…
Bref, tout ce qui nécessitait le recours à javascript ou à des technologies propriétaires sera désormais “livré d’origine”.
La grosse nouveauté est donc de proposer un nouveau schéma de structuration des données qui va venir remplacer les éléments en bloc et en ligne (cf. HTML5 se dévoile) :
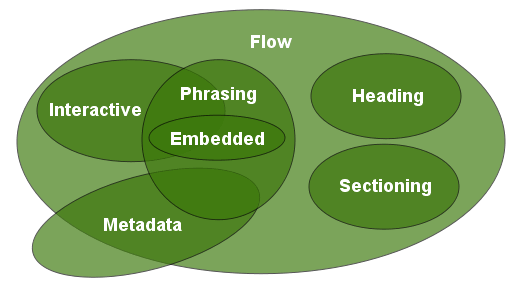
Le "content model" de HTML 5
Les spécifications manquent de précisions pour se faire une idée de ce nouveau schéma, d’autant plus que de nouvelles balises structurantes comme <template> et <datatemplate> ont été introduites.
Gros changement également avec un jeu de nouvelles balises permettant de mieux définir le contenu : <header>, <nav>, <article>, <aside> et <footer> :
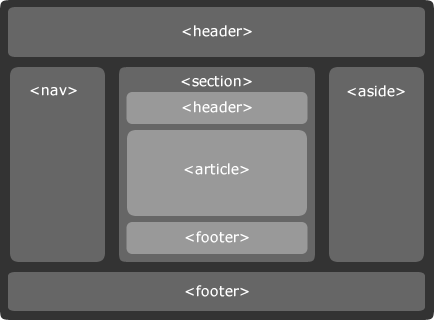
Les nouvelles balises de structuration du contenu de HTML5
C’est donc une petite révolution puisque ces nouvelles balises vont permettre une structuration beaucoup plus propre des pages, surtout pour les sites avec beaucoup de contenus (blogs, portails…). Plus d’infos ici : HTML5 and The Future of the Web.
Notons enfin l’apparition de balises très intéressantes comme <audio> et <video> pour les éléments multimédias, <canvas> pour les dessins vectoriels ou encore <datagrid> pour les tableaux de données. Ces nouvelles balises permettront de réduire la dépendance à des technologies propriétaires comme Flash. Juste un dernier mot sur les formulaires qui vont avoir de nouveau types de champs <input> comme date, time, number, range, email, url, search, color…
Je pense qu’il n’est pas faux de dire qu’avec HTML 5 la séparation entre contenu, structure et présentation sera encore plus facilement gérable.
Quelles nouvelles possibilités pour CSS 3 ?
Précisions que du côté des feuilles de styles, les travaux autour des nouvelles spécifications CSS 3 sont beaucoup moins perturbés. Cela permet donc d’avancer plus vite. Quoi que… j’ai dans mes archives des articles sur le sujet datant de 2004 et 2005 : Des formulaires standardisés, CSS 3 : des templates pour structurer vos pages web et Formulaires : quand les CSS 3 vous changent la vie.
L’essentiel des travaux autour des CSS 3 a été de standardiser des propriétés pour réaliser des traitements graphiques qui nécessitaient auparavant des astuces :
- Border-radius pour les coins arrondis ;
- Text-shadow pour les ombres portées ;
- Transparency et Opacity pour la transparance ;
- Animation et Transition pour les animations (cf. Nicer Navigation with CSS Transitions, à regarder avec les dernières versions de Safari ou Chrome)…
Bref, il y a beaucoup de nouveautés à découvrir ici : 7 New Essential CSS 3 Techniques Revealed. Tout l’intérêt étant de pouvoir se passer d’images ou d’astuces pour pouvoir réaliser ce que l’on souhaite. Illustration avec ces jolis boutons :

De jolis boutons sans image avec CSS 3
Encore plus intéressant, toutes les propriétés concernant la mise en page et le positionnement : Presentation Levels, Template Layout, Multi-column Layout, Grid Positioning et Flexible Box Layout.
Le changement va être aussi spectaculaire que radical : là où il fallait tout un tas de <div> imbriqués, d’images, de tableaux… pour arriver à la mise en page et au traitement graphique souhaité (donc en alourdissant le code source), nous aurons bientôt une syntaxe bien plus lisible grâce à ces nouvelles propriétés.
Quels bénéfices et pour quand ?
Je vous propose de récapituler ce que nous venons de voir : un contenu mieux structuré et défini, une syntaxe allégée, des traitements graphiques standardisés… tout ceci va permettre d’avoir un code source beaucoup plus propre. Ceci est particulièrement important dans la mesure où les pages ne sont plus faites à la main pour des utilisateurs humains, mais générées par des systèmes de gestion de contenu et exploitées à la fois par des humains et des agents intelligents (via les balises descriptives ou microformats).
C’est donc une authentique révolution à laquelle nous allons assister… dans quelques années ! Hé oui, car même si les spécifications sont là, leur implémentation est fonction du bon vouloir des éditeurs de navigateurs et du taux de renouvellement par les utilisateurs.
Aujourd’hui le marché est encore dominé par un IE qui risque d’aggraver encore son retard avec ces nouvelles spécifications. Vient ensuite Firefox qui évolue vite (grâce à une communauté très active) mais qui est tout de même fortement ralenti par l’inertie des utilisateurs (surtout lorsque les parts de marché dépassent les 30 %).
Il est certain que les choses sont beaucoup plus simples pour Safari, Opera ou encore Chrome qui peuvent avancer à leur rythme (lire à ce sujet : Opera 10, Chrome 4, Firefox 4 : Vers des plateformes sociales et applicatives).
Donc au final, l’impact ne se fera pas ressentir avant quelques années. Sauf si un éditeur trouve le moyen de faire avancer les choses au forcing (au hasard Google avec son futur Wave qui tournera bien mieux sur Chrome).
Google Wave, une application en ligne taillée pour HTML 5 et Chrome
Par contre, une fois que le parc de navigateurs aura été renouvelé, j’anticipe un gros changement au niveau de l’industrie du web avec une montée en puissance de profils comme les architectes front office (l’équivalent des DBA ou des architectes systèmes) chargés de concevoir des interfaces web cohérentes et surtout performantes (notamment dans la gestion des styles).
De même, j’anticipe une véritable révolution pour les outils de prototypage rapide dont l’intérêt était limité du fait du format de sortie (du HTML de base que ne pouvaient pas exploiter les équipes de production) et qui vont fortement bénéficier de cette épuration du code source et de la séparation structure / contenu /présentation.
Bref, j’ai l’impression de me répéter, le web a de très beaux jours devant lui avec ces nouvelles spécifications qui vont tranquillement nous amener vers des contenus mieux structurés (sémantisés) et des applications en ligne plus performantes et simples à créer / maintenir.
Avec la rentrée viennent les bonnes résolutions de la rentrée. Une de mes premières résolutions est donc d’arrêter de publier des article sur Twitter, ou du moins d’en publier moins car j’ai comme l’impression que nous approchons de la saturation. Mais il faut dire que malgré son apparente simplicité, Twitter a l’incroyable faculté d’hypnotiser la blogosphère au point d’en devenir un des sujets de prédilection depuis près de 2 ans. À tel point que l’on se demande quel sujet va venir éclipser la Twittmania : Il y a une vie après Twitter (heu… laquelle déjà ?).
Plutôt que de revenir sur les clés du succès de Twitter, je préfère essayer de me projeter et de lister différents scénarios d’évolution possibles. Vos remarques et propositions sont bien évidemment les bienvenues dans les commentaires.
Scénario 1 : La ligne de commande du web
Dans un précédent article j’avais comparé Twitter à la CB du web. Mais lorsque je regarde les différents services gravitant dans l’écosystème de Twitter, je me dis qu’une évolution possible serait de “standardiser” de fait les tweets pour en faire des instructions façon lignes de commande. Mais si enfin, des lignes de commande comme il est possible d’en saisir quand vous êtes en mode “console”. Twitter deviendrait donc une gigantesque console à l’échelle du web, une interface textuelle qui permet aux utilisateurs et aux services de communiquer entre eux.
L’intérêt des interfaces à lignes de commande est leur souplesse et leur évolutivité. De nombreuses fonctions et informations sont ainsi publiées sur Twitter avec une syntaxe bien particulière pour pouvoir être utilisées ultérieurement par des services extérieurs. Concrètement il s’agit de services en ligne qui vont parcourir la Twittosphère et récupérer les tweets qui utilisent la bonne syntaxe pour proposer une lecture plus simple.
Premier exemple avec Boarding qui permet de recenser les voyageurs en transit et faire des rencontres informelles dans les aéroports. Exemple de syntaxe : “#boarding in cdg for yyz” = “J’embarque à Paris pour Toronto“.
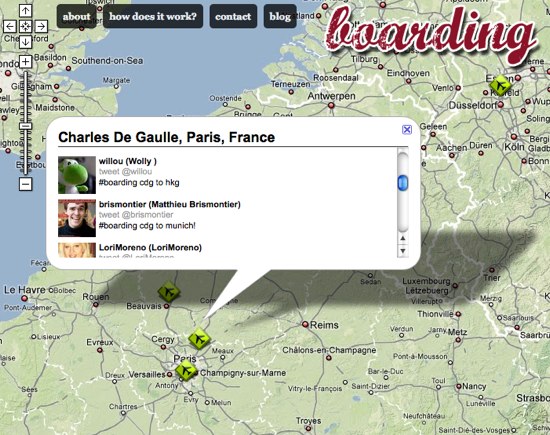
L'interface de Boarding pour les voyageurs en transit
Il y a également StockTwits qui analyse les tweets relatifs aux sociétés cotées et permet d’en faire une synthèse, il suffit pour cela d’insérer le ticket Nasdaq de la société dont vous parlez précédé du symbole $ :
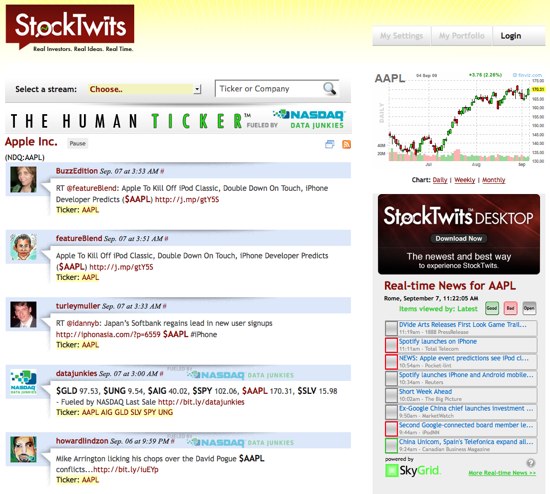
StockTwits pour les boursicoteurs-tweeteurs
Dans le même style il y a aussi PollyTrade, un service qui vous permet de passer des ordres du type “@pollytrade buy 100 shares AAP“. Plus d’infos ici : Boursicoter avec Twitter.
Pour les fans de ciné il y a aussi FlixPulse qui agrège les avis de la Twittosphère :
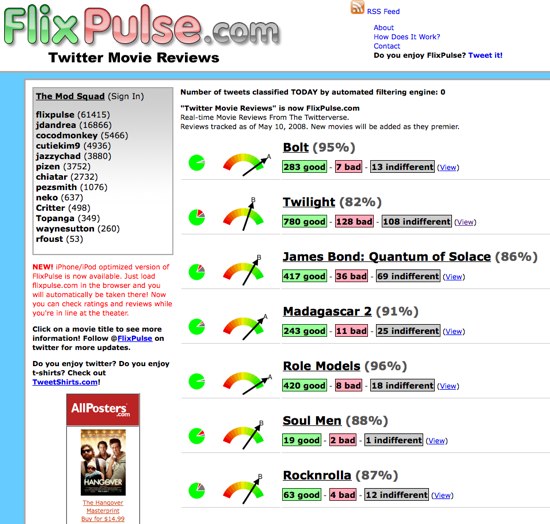
Les critiques de film avec FlixPulse
Il existe également un service de rating plus ouvert (Out of 5) qui utilise un principe équivalent mais sans possibilité de faire des moyennes.
On retrouve enfin un service de rencontre (Radaroo) qui utilise une syntaxe assez complexe :

La syntaxe du service de rencontre Radaroo
Notons également le très particulier Ideas Culture qui permet de faire des demandes de recherche d’informations qui sont traitées dans la nuit par des équipes travaillant en Australie : Services uses Twitter to crowdsource ideas overnight.
Bref, tous ces exemples me font dire que la simplicité de Twitter et surtout les nombreuses possibilités offertes par les API permettent de développer tout un tas d’usages autour de cette fonction de ligne de commande.
Scénario 2 : le nouveau flux RSS
Quoi que l’on puisse en dire, et même si je suis un fan de la première heure, les flux RSS ne sont pas réellement entrés dans les habitudes du grand public, ni même des collaborateurs en entreprise. Pourtant il existe un réel besoin d’un flux d’informations brutes (de type flux AFP) que Twitter pourrait bien combler. C’est en tout cas le point de vue de certains : Rest in Peace RSS et Twitter humanise la technologie RSS. Les arguments avancés sont qu’avec Twitter la masse d’utilisateurs permet de faire du filtrage collaboratif sur les infos et que l’on trouve plus facilement son ou ses “fournisseurs” en fonction des affinités que vous avez avec lui (ou elle).
Je ne rentrerais pas dans le débat de savoir si les abonnés RSS ont plus de valeur que les followers (cf. RSS Subscribers or Twitter Followers: Which Are Worth More?) mais je pense qu’il serait juste de dire que Twitter est un très bon canal d’informations en temps réel pour celles et ceux qui veulent surveiller de loin, mais que pour une activité de veille plus intensive et systématique, les flux RSS sont tout de même recommandés.
Tout ça pour dire que dans certains domaines, Twitter est utilisé comme un canal de diffusion en temps réel :
- Pour l’actualité chaude (@CNN_Live_News, @CNNbrk) ;
- Pour les cours de bourse (NASDAQ Launches Live Stock Quotes On Twitter) ;
- Pour des offres d’emploi (10 Comptes Twitter pour Retrouver un Emploi) ;
- Pour les annonces immobilières (15 Comptes Twitter dédiés à l’Immobilier)…
Bref, il existe autant de domaines d’application que de types d’information. En ce qui concerne l’immobilier, il existe même des robots capable de répondre à des requêtes : RealEstate.com Launches Useful Twitter Bot. (ha non mince, c’est plus de la ligne de commande ça).
Scénario 3 : Une plateforme de jeux en temps réel
Les jeux ont toujours été un vecteur très performant de sociabilisation, et Twitter peut faire entrer cette sociabilisation dans l’ère du temps réel en permettant aux joueurs de rester en contact ou de se rencontrer avec des services comme TweetMyGaming (TweetMyGaming Compiles Video Game Conversations from Twitter in Real-Time) ou Twoof (qui permet de lier vos deux comptes Doof et Twitter) ou de partager les réactions des joueurs au cours d’une partie (How Twitter is Changing the World of Professional Poker).
Mais les applications les plus intéressantes sont celles qui concernent les jeux en ligne directement intégrés à Twitter, ou du moins qui se servent de Twitter comme canal d’interaction (MSPOG + microblog = Micro social RPG) et qui représentent un marché juteux (Virtual Mafia Game Making Actual Money on Twitter).
Même s’il existe déjà de nombreuses plateformes sociales dédiées aux joueurs (RaptR, GamerDNA…), c’est encore une fois Twitter vers lequel les regards se tournent : Can Twitter Become the New Casual Gaming Hub? Pourquoi ? Toujours pour les mêmes raison : simplicité, ouverture, modularité…
Conclusion
J’arrête là ma liste de scénarios d’évolution possibles car il faut que je vous en laisse aussi ! Plus sérieusement, je constate que la stratégie de Twitter qui consiste à complètement ouvrir sa base de donnée au travers de nombreuses API a été payante pour gagner très rapidement en popularité et surtout en ferveur. Dans un avenir proche il pourrait être tout à fait envisageable d’exploiter un service reposant sur Twitter sans que vous ayez à passer par Twitter.com (inscription, autorisation, manipulation…), tout serait délégué à des services tiers et Twitter serait alors une sorte de couche de communication.
Une évolution intéressante qui, de plus, pourrait devenir un modèle économique pour Twitter qui ne facturerait pas les utilisateurs mais les services qui exploitent sa base de données.
Alors selon vous Twitter peut-il réussir cette forme de reconversion ?
Prenez un ordinateur classique tel qu'il a été conçu par Von Neumann...
Se pourrait-il que la lenteur des développements en intelligence artificielle soit due à un composant électronique manquant ? C’est l’idée surprenante développée dans un récent article du très sérieux
New Scientist.
Il existe aujourd’hui trois types de composants électroniques fondamentaux : la résistance, la bobine et le condensateur (le plus connu des composants, le transistor serait en fait un genre de résistance). Dès 1971, Leon Chua, de l’université de Berkeley avait émis l’hypothèse d’un quatrième élément : le memristor, expliquait-il serait en mesure de se souvenir des courants qui l’ont traversé auparavant.
Les théories de Chua affirmaient qu’un tel “memristor” pouvait exister, mais il n’existait aucun système capable de réaliser cette prouesse dans le monde réel. Jusqu’à ce que Stan Williams, chercheur à Hewlett Packard, réalise un tel procédé au niveau nanométrique.
Il a utilisé pour cela des assemblages de molécules de dioxyde de titanium. Il a soumis son nanosystème à certains voltages, qui, selon la direction du courant, le transformait en conducteur ou semi-conducteur. Si ensuite on coupait l’électricité, le processus s’arrêtait. Mais si on relançait le courant par la suite, le système reprenait immédiatement son état antérieur.
Première conséquence : la possibilité de construire des mémoires “flash” beaucoup plus efficaces. En effet, l’effet memristor “s’use” et ne fonctionne environ que 10 000 fois avant de s’effondrer. Cela rend les memristors peu utilisables pour construire des mémoires d’ordinateurs, mais les mémoires flash qui s’usent au même rythme pourraient avantageusement être remplacées. Mais, toujours selon le New Scientist, là n’est pas le plus important : le memristor serait la clé de l’intelligence artificielle.
La mémoire est-elle la clef de l’intelligence artificielle ?
Pour expliquer pourquoi, l’auteur de l’article appelle à la rescousse une des créatures les plus bizarres de notre planète : le Physarum Polycephalum.

Image : CC Un Physarum polycephalum par Sentrawoods.
Cette curieuse forme de vie plus ou moins apparentée aux champignons vit dans les forêts et présente l’aspect sympathique d’une gelée gluante. Il s’agit en fait d’une amibe, d’un unicellulaire de taille gigantesque. Ce n’est même pas un animal, mais elle n’est pas aussi bête qu’elle en a l’air. Elle réagit à son environnement et est même capable de trouver son chemin dans un labyrinthe. En fait, certains chercheurs ont même travaillé à lui faire” piloter” un robot ! Mais il y a plus. Exposée à une série de stimuli répétitifs, elle s’est montrée capable de “prévoir” un évènement susceptible de se produire, comme un bon chien de Pavlov. En effet, soumise à une série de changements de températures, la créature se met au bout d’un certain temps à réagir à l’avance à ces modifications.
Comment cet organisme arrive-t-il à se souvenir sans le moindre neurone ? Pour Max Di Ventra, physicien à l’université de Californie, les éléments constitutifs de l’amibe pourraient bien se comporter comme des memristors. Capables de se souvenir des états vécus précédemment, ils reprendraient éventuellement une configuration spécifique déjà employée face à certains évènements. Ventra et son équipe se sont attachés à prouver leur hypothèse en construisant un circuit électronique analogue à la moisissure, comprenant bien sûr des memristors. Celui-ci devint vite capable, à son tour, de “prévoir” les courants électriques qui allaient le traverser.
Les capacités mémorielles du Physarum Polycephalum seraient la preuve que le développement de l’intelligence passe par un système de type memristor. Un collègue de Stan Williams à HP, Greg Snider, travaille sur la création de synapses électroniques capables de se conduire comme les vrais. Selon lui, l’existence de tels composants nanométriques permet justement des applications d’intelligence artificielle qu’une simulation au niveau électronique n’autorise pas, pour une simple raison : la densité. Rappelant qu’il existe plus de 1010 synapses par centimètres carrés de cerveau, soit une densité 10 fois supérieure à celles des microprocesseurs actuels, il précise avec la force de l’évidence : “C’est une importante raison pour laquelle les machines intelligentes ne se promènent pas dans la rue.”
“Les gens confondent ce que nous faisons avec les réseaux neuronaux”, renchérit Williams. “Mais les réseaux neuronaux - la voie la plus prometteuse, jusqu’ici, pour créer un cerveau artificiel - reste du software fonctionnant sur du matériel standard. Ce que nous visons, nous, est un changement d’architecture.”
Changer l’architecture de la mémoire
Steve Grand, l’auteur du jeu “expérimental” Creatures et spécialiste de la vie et de l’intelligence artificielle, n’est pas aussi enthousiaste. Certes le memristor est intéressant, mais selon lui l’auteur de l’article (et les chercheurs qu’il cite) commet une erreur fondamentale.
“Je ne peux empêcher, explique-t-il, de trouver qu’il existe un sérieux problème dans la manière dont les physiciens et les mathématiciens réfléchissent à la biologie.”
“Un ordinateur est bien sûr un système électronique, mais le point le plus important à ce sujet est qu’un ordinateur est capable de simuler n’importe quelle autre machine. Donc ils peuvent également simuler des memristors. Ils n’ont pas besoin d’être construits avec : ils les simulent sous forme de code, comme ils le font pour toute chose. Je suis sûr que j’ai écrit de nombreuses fois du code qui possédait un état mémoire analogue à celui d’un memristor (…). Il n’y a qu’un physicien pour confondre le hardware et le software comme ça. Ça me dépasse”.
“La science classique a parfois la mauvaise habitude d’être obsédée par les quantités et d’oublier, voire de nier l’existence, des qualités. (…) La raison pour laquelle nous ne comprenons pas le cerveau n’a rien à voir avec un “composant manquant”. La raison pour laquelle nous ne le comprenons pas est que nous ne saisissons pas le CIRCUIT. La mémoire, les pensées, les idées et le moi ne sont pas des propriétés des composants du cerveau, mais de son organisation.
(..) La vie et l’esprit sont des constructions qualitatives. Chercher le secret d’un mystérieux élixir vitae est une complète erreur”.
Sans doute, les memristors permettraient de créer des intelligences artificielles qui ne nécessiteraient pas des corps cybernétiques de 4 m3, ou qui ne mettraient pas une heure pour formuler la pensée la plus simple. D’un autre côté, l’absence des memristors ne saurait expliquer et justifier les difficultés rencontrées par les chercheurs en intelligence artificielle. Il semble bien qu’il y ait là une barrière théorique qui va bien au-delà de l’usage de tel ou tel composant.
Alors hardware ou software ? Les paris restent ouverts !
intelligence artificielle, mémoire



