 Liste de partage de Grorico
Liste de partage de Grorico
Le site de réseauratage social Facebook refile des quantités énormes de données personnelles aux sociétés d’études de marchés.
Les membres seront bientôt envahis de spams venus des multinationales du commerce de trucs dont vous n’aviez pas besoin mais qui vous sembleront soudainement indispensables.
Ces sociétés pourront poser des questions à des membres triés sur le volet qui se sentiront soudainement pousser une vie. Il faudra peu de temps avant que votre compte ne soit supprimé si vous ne répondez pas aux questions.
Randi Zuckerberg, directrice des marchés mondiaux pour Facebook, et éventuellement sœur du fondateur Mark Zuckerberg, dit que les multinationales sont remplies de joie de se voir offrir la possibilité de spammer autant de monde qui n’aurait jamais pensé recevoir un tel traîtement privilégié par ce biais.
Elle se réjouit d’avoir autant de multinationales qui pensent: “ce serait vraiment formidable pour nos affaires”.
Elle n’a pas mentionné combien de clients de Facebook se sont déjà plaints d’une telle éventualité.
L’Inq
Telegraph
Traduction et adaptation d’un article de Nick Farrell pour INQ.
La sortie de Native Client, une technologie encore expérimentale du Google Labs, est passée complètement inaperçue à quelques rares billets près. Le problème n’est pas que les blogueurs soient peu inspirés par cette nouvelle, mais plutôt que ce produit a tellement été mal présenté au public que personne ne sait trop à quoi ça va servir. Pour information il m’a fallu près de deux semaines de cogitation avant d’attaquer la rédaction de ce billet.
Pas réellement un concurrent de Flash ou de AIR
Force est de constater que ce nouveau produit est plutôt obscur, que les explications sont rares et que même les équipes à l’origine de ce projet sont incapables de fournir une explication claire (cf. Native Client: An OS in Your Browser). Pour faire simple, Native Client est une extension que vous installez sur votre ordinateur pour pouvoir exécuter au travers de votre navigateur des applications en ligne écrites en code natif (C ou C++). Si vous avez le courage vous pouvez toujours lire l’annonce officielle mais vous n’y apprendrez pas grand chose de plus : Native Client, A Technology for Running Native Code on the Web.
Ne vous y trompez pas, même s’il est beaucoup question de RIA, NaCl n’est ni un plugin à la Flash ou Silverlight, ni un runtime à la AIR. Ce n’est pas non plus une technologie qui exploite une machine virtuelle à la JavaFX et pour finir c’est encore moins un mini-système d’exploitation. En fait c’est un peu tout ça à la fois (bien que pas tout à fait). Lire à ce sujet : Why Google Native Client is not a Flash competitor.
En tout cas le moins que l’on puisse dire c’est que Native Client laisse un certain nombre d’observateurs avertis très sceptiques : Google Native Client: A Game Changer or an Also-Ran? et Google Native Client: web deluxe, or ActiveX redux?.
Avec Native Client ne gaspillez plus la ressource de votre processeur
Pour bien comprendre tout l’intérêt de Native Client (NaCl pour les intimes), il faut se pencher sur l’architecture des ordinateurs et surtout sur le fonctionnement des plug-in. Pour faire simple un ordinateur est composé de couches matérielles (la carte mère, le processeur, la carte graphique…) et de couches logiciels (le système d’exploitation, les applications…). Quand vous consultez une interface riche en Flash, celle-ci repose sur du code qui est interprété par le plug-in, par le navigateur, par le système d’exploitation et finalement par le processeur. Ce dernier traite l’instruction et remonte un résultat dans l’autre sens. Toutes ces couches sont autant d’intermédiaires qui traduisent, interprêtent et ne font que vous gaspiller de la ressource (mémoire et puissance de calcul). Voilà pourquoi les animations 3D exécutées dans Flash vous paraissent minables comparé à ce que votre carte graphique est capable de faire.
Avec Native Client, la promesse est de ne plus gaspiller cette ressource en évitant les intermédiaires (les différentes couches logicielles) et de faire en sorte que les applications en ligne exécutées dans votre navigateur ne soient que 1% moins lentes que celles qui sont installées sur le système d’exploitation. Lire à ce sujet l’excellent mais très technique article de Samy : Avec Native Client, Google invente l’OS dans le navigateur.
Si la promesse est belle (des performances sans commune mesure) et l’exploit technologie réel, il y a une contre-partie : les applications en ligne doivent être développées en C ou C++. Et c’est là où ça coince : le C et le C++ sont des langages de programmation contraignants qui ne sont pas réellement adaptés aux interfaces riches. Il existe maintenant de nouveaux langages beaucoup plus sophistiqués qui se sont imposés sur ce créneau avec des environnement de développement dédiés beaucoup plus productifs (à l’image d’ Eclipse ou de Flex Builder). Donc concrètement pour bénéficier des performances de NaCl il faut revenir 20 ans en arrière et se réapproprier des langages qui font dramatiquement chuter la productivité. En clair il va vous falloir beaucoup plus de temps pour développer la même application. Tout ça pour quoi ? Pour de meilleures performances, mais est-ce que la performance est réellement un problème ?
PS : Ceci est une tentative naïve de l’auteur d’expliquer de façon simple le fonctionnement des ordinateurs pour pouvoir mieux comprendre la prise de position sur NaCl. Les premières versions de cette explication étaient approximatives et ont engendrés des commentaires très aggréssifs qui ont polués la discussion avec un débat de forme (”le C n’est pas mort et il est plus performant que Java”) au détriment d’une discussion de fond (NaCl est une belle avancée technologique mais qui ne trouvera pas forcément son public dans la mesure où les usages de l’outil informatique sont amenés à beaucoup changés dans les prochaine années, notamment avec les approches centrées sur la collaboration de l’Entreprise 2.0).
Le faux débat de la performance
Oui, la performance est importante, car il en faut pour faire tourner dans votre navigateur des applications équivalentes à ce que vous avez sur votre disque dur. Mais d’un autre côté est-ce que c’est un but légitime ? Traduction : Quel est l’intérêt de faire tourner Word 2007 dans votre navigateur quand un wiki peut vous apporter un bien meilleur service ? Quel est l’intérêt de faire tourner un mastodonte comme Photoshop dans votre navigateur alors que dans 90% des cas vous pouvez vous suffir de Photoshop Express ou de Picnick ?
Nous entrons ici dans la partie délicate de la discussion autour de NaCl, la partie où l’on va se rendre compte que cette technologie est surtout révolutionnaire pour les éditeurs de logiciels, pas pour les concepteurs d’interfaces riches. L’industrie du logiciel est en effet en train de se scinder en deux clans : d’un côté les applications lourdes (Photoshop, 3DSMax…) qui sont avant tout destinées à un petit nombre de professionnels spécialisés dans un domaine et nécessitant beaucoup de ressources (mémoire, puissance de calcul, capacité de stockage…), de l’autre des applications plus légères ( SalesForce, Basecamp…) qui sont avant tout orientées collaboration et qui consomment très peu de ressources. Le modèle SaaS est donc parfaitement adapté à la seconde catégorie avec des technologies parfaitement maîtrisées (HTML + Javascript, Flash…) qui ne posent pas de problème de performance.
Vous pourriez me dire que le débat sur la performance est revenu sur le devant de la scène avec la mode des ordinateurs low cost (les EeePC et autres netbooks) qui ne disposent pas du tout de la même puissance de calcul. Pour ce segment bien particulier il serait intéressant de voir s’il est rentable d’adapter des applications desktop existantes pour les reformater aux contraintes de ces ordinateurs (petit écran…). Mais encore une fois la solution se trouve plutôt dans une nouvelle approche de l’outil informatique (avec les intranets wikifiés et les mashups d’entreprise) plutôt que dans l’exploit technique de faire tourner Office 2007 et Vista sur un EeePC.
Ceci est d’autant plus vrai que les dernières versions de navigateurs comme Firefox, Opera ou Chrome ont fait un bond spectaculaire et ont réussi à décupler les performances d’exécution de code Javascript. Et comme une bonne nouvelle ne vient jamais seule, les plug-in progressent aussi à pas de géant puisque Flash 11 et Silverlight 3 devront également marquer une nette rupture de performance avec une prise en charge beaucoup plus poussée de l’accélération matériel, donc un recours plus intensif aux composants hardware (notamment la carte graphique) et moins de gaspillage de mémoire. Ca ne vous rappelle rien ? Bref, toutes ces améliorations à venir nous font relativiser le gain de performance annoncé par NaCl. Mais bon… l’idée n’est pas neuve car Microsoft avait tenté d’introduire une technologie équivalente avec les fameux ActvieX (cf. Google Native Client : Un ActiveX-Like ?) et n’oublions pas non plus que le javascript a ses limites (cf. L’invasion des machines virtuelles).
Donc au final NaCl doit être avant tout considéré comme un environnement d’exécution et de déploiement révolutionnaire car il permet aux éditeurs de ne développer qu’une seule version de leurs applications et de les distribuer via le web (en évitant les circuits de distribution classique avec boîtes et DVD). Vous noterez au passage que cette solution n’a été rendu viable que depuis l’adoption d’une architecture commune (x86) par les constructeurs et éditeurs de système d’exploitation (Microsoft / Windows, Apple / Mac OSX, Linux). Pour en savoir plus sur le potentiel de NaCl dans ce domaine je vous recommande cet article de Louis Naugès : Web 2.0, Lla marginalisation, définitive, de Windows sur les PC.
C’est quoi déjà une interface riche ?
Mais revenons à nos moutons : les interfaces riches. Dans la vision de Google, les interfaces riches sont avant tout destinées à être exploitées dans le cadre d’applications en ligne. Mais cette vision est très réductrice car que fait-on des innombrables interfaces riches qui reposent sur de la vidéo, des animations, du son, des transitions et autres effets spéciaux ?
Même si Native Client intègre un moteur de rendu vectoriel, Flash (et dans une certaine mesure Silverlight) reste la technologie la plus appropriée et de très loin pour faire ce type d’interface. Est-ce que vous vous imaginez faire un carrousel, un configurateur ou un assistant au choix en C ou C++ ? Non bien évidement car ce n’est pas pour cela que ces langages ont été conçus. L’avantage de Flash est d’autant plus net qu’il est couplé avec un environnement de production parfaitement adapté à ce type d’interface ainsi qu’une infinité de bibliothèques prêtes à l’emploi pour gagner du temps. Vous noterez que l’approche de Google centrée sur les applications en ligne se vérifie également avec d’autres produits comme GWT, un framework Ajax qui est exclusivement tourné vers une logique applicative.
Bref, ce n’est pas demain que nous allons voir des studios de production comme 2advanced, Blitz, Megalos ou Soleil Noir abandonner Flash pour faire du C. Ces studios sont capables de faire des prouesses que le C n’autorise pas.
Conclusion
Si nous résumons :
- NaCl n’est pas un plug-in, c’est un projet encore expérimental qui n’est même pas en phase alpha ;
- NaCl n’est pas un mini-système d’exploitation, c’est un complément qui permet de court-circuiter des intermédiaires pour profiter des pleines performances du matériel ;
- NaCl n’est pas concurrent de Flash ou Silverlight qui sont bien plus performants pour faire de belles interfaces riches ;
- NaCl dépend de langages de programmation (C et C++) qui sont plus plus performant mais plus contraignant ;
- NaCl propose une approche tout à fait intéressante de la distribution de logiciels, mais les gros éditeurs disposent de leviers très puissants (accords cadres, partenariats, lobbying…) pour défendre leur modèle de distribution (et je ne parle pas que de Microsoft).
Voilà pourquoi NaCl va très certainement chambouler la longue traîne de l’industrie logiciel bien que cette technologie ne soit en l’état pas viable pour survivre sur le marché des RIA. Marché déjà bien encombré avec Flash, Silverlight, JavaFX ou des acteurs de niche comme Curl ou Unity3D (respectivement pour des applications en ligne d’entreprise et pour des jeux en 3D comme Cmune).
Reste donc deux possibilités : Soit Google fait fortement évoluer son produit pour le rendre réellement attractif (en expliquant clairement ce à quoi il sert et ce qu’il n’est pas), soit NaCl restera une expérimentation intéressante mais qui sera confinée à un usage interne chez Google.
ous n'avez pas pu louper cette annonce. Une bande de joyeux lurons est parvenue à créer une autorité de certification en générant un vrai faux certificat X.509 d'autorité par le truchement d'une collision MD5. Ce que pas mal de gens se sont empressé de reprendre sous des titres du genre "j'ai mal à mon SSL"...
Et de glisser sur l'évidente peau de banane qui se cachait derrière ce talk donné à l'occasion du 25e CCC. Car sans minimiser la qualité du travail du fourni et son impact potentiel sur les communications qualifiées de sécurisées sur le web, ils sont tout de même loin d'avoir, comme on le dit çà et là, cassé SSL.
Je ne vais pas reprendre les détails de l'attaque qui sont très clairement expliqués sur le site monté par les sept chercheurs[1] en question ou plus simplement sur les slides de la présentation. De manière générale, l'attaque a consisté à créer une paire de certificats dont les parties sujettes à signature avait la même somme MD5. Une collision choisie en somme. Les bases théoriques permettant ce genre de choses remontent à 2004, et surtout aux améliorations notables qui ont ensuite été produite en 2006 puis en 2007 pour obtenir le résultat escompté.
Le point délicat de la technique est, une fois trouvée la paire de certificats qui va bien, dont un servira à usurper la CA, de se faire signer l'autre par une des autorités de certification[2] qui utilisent encore MD5 comme condensat pour leurs signatures. Ce qui veut dire en gros leur acheter un certificat serveur dont le contenu sera exactement celui attendu. Et c'est là que, parmi les six CA potentiellement attaquables, RapidSSL[3] entre en jeu. En effet, outre le fait qu'elle ait produit l'immense majorité de certificats signés en MD5 collectés par l'équipe, son système de génération de certificats présente une prédictibilité très appréciable :
- les numéros de série des certificats sont incrémentés à chaque requête ;
- il se passe exactement six secondes entre la demande de certificat et sa génération.
Ces deux aspects permettent alors de prédire facilement la période de validité, qui débute à la seconde près à la génération du certificat, et le numéro de série. Après plusieurs essais, ils vont obtenir de RapidSSL exactement le certificat serveur qu'ils attendaient, dûment signé, et qui possède la même somme MD5 que le faux certificat de CA précédemment préparé. Même somme MD5, donc même signature. Les voilà en possession d'un certificat d'autorité valide, parce que signé par la vraie CA de RapidSSL d'une part, et portant l'attribut de CA positionné en contrainte de base d'autre part...
C'est je pense ce qu'il faut retenir. Ils n'ont pas généré un faux certificat dont la signature était la même que celui de la véritable CA de RapidSSL, ce qui revient à trouver une seconde pré-image. Ils ont généré une collision soigneusement choisie entre deux certificats pour que l'un des deux ait l'attribut de CA et que l'autre puisse être généré et signé sur demande. Autant dire que cela demande du travail et des conditions favorables. Merci RapidSSL pour avoir réuni toutes ces conditions...
Les conséquences de tout ça ? C'est là qu'il faut être extrêmement prudent pour ne pas sauter du coq à l'âne. La conséquence d'une telle attaque pourrait être résumée de la façon suivante : elle permet de faire valider des certificats arbitraires par tous les systèmes qui font confiance à la CA de RapidSSL. Avec les conséquences qu'on imagine. Parce qu'au delà des considérations techniques précédemment évoquées, il s'agit avant tout d'un problème qui touche le moyen et l'objet principaux de toute PKI : l'organisation et la confiance.
Je m'explique. Quand on dit SSL, on pense immédiatement HTTPS. Et c'est bien naturel dans la mesure où il s'agit de la principale application utilisant ce protocole cryptographique. Du moins la plus visible et populaire. Ce n'est cependant la seule. Loin s'en faut. Mais je vais y revenir. L'aspect particulier de HTTPS et du système de distribution de confiance, que beaucoup qualifient de PKI, qui l'entoure, c'est qu'en tant qu'utilisateur, vous faites aveuglément confiance à un nombre particulièrement important de CA indépendantes les une des autres et pour la plupart commerciales. Pour vous donner une idée, le paquetage Debian ca-certificates contient pas moins de 140 certificats de CA. Ça fait pas mal de monde à qui votre navigateur, entre autres, fait confiance. Et parmi eux se trouve évidemment le fameux certificat RapidSSL. Et c'est bien là que le bât blesse. À partir du moment où vous lui faites confiance, c'est tout le système qui s'écroule puisque l'attaquant est non seulement capable d'usurper les certificats de tous les sites utilisant leurs certificats, mais également tous les autres ! Dans un scénario de type MitM par exemple, il suffira de générer à la volée un faux certificat signé par la CA factice et de fournir les deux en bundle au client. Et le tour est joué. C'est bête comme choux, l'attaque ne date pas d'hier et on sait faire depuis très longtemps...
Cependant, comme je le disais précédemment, HTTPS n'est pas la seule application qui repose sur SSL/TLS et/ou des certificats X.509. On pensera par exemple au courrier électronique, avec des protocoles comme IMAPS ou l'extension STARTTLS qu'on trouve principalement dans ESMTP, les nombreux mécanismes d'authentification basés sur X.509, typiquement quelques méthodes EAP comme PEAP ou EAP-TLS, ou encore tout ce qu'on appelle usuellement VPN SSL. Pour ne citer que ces quelques applications particulières. Dans l'absolu, toutes ces applications devraient être impactées par cette attaque, comme le précise le SANS. Sauf qu'elles ont quelque chose de particulier : elles n'ont pas besoin de faire confiance à plus d'une centaines d'organisations. En tout cas un nombre extrêmement limité d'entre elles. En fait, vous pouvez même n'accorder de confiance à personne d'autre que vous-même, en gérant votre propre CA interne, et ce que font la plupart des gens dans cette situation. Car à bien y réfléchir, votre client de courrier électronique n'a pas besoin de faire confiance à Verisign pour valider le certificat de votre serveur IMAP. Pas plus que votre supplicant 802.1x n'a à truster Thawte pour authentifier le serveur RADIUS de votre infrastructure Wi-Fi. Et même pour des applications comme S/MIME, la confiance à des CA indépendante, donc non maîtrisées, devrait être toute relative. Et on pourrait se prendre à rêver d'un client Web dont la liste de certificats racine serait drastiquement réduite, mais est-ce bien crédible ?
Tout ça pour dire qu'il y a pleins d'usages de SSL/TLS qui sont largement moins impactés que HTTPS par une telle attaque, quand elles y sont exposées. Typiquement, il est fort peu probable que les compères en questions puissent obtenir un certificat émis par une CA à usage privé. Et quand bien même ils le pourraient, je doute que le processus de génération satisfassent les conditions dont ils ont besoin pour mener l'attaque à bien, dans la mesure où il n'a, la plupart du temps, rien d'automatique. Comme je le disais plus tôt, loin de moi l'idée de minimiser la portée de ces travaux. Juste positionner le problème au bon endroit.
Maintenant, comment on corrige tout ça ? D'abord, quand on est CA, en n'utilisant pas MD5 pour signer des certificats. Passer à SHA-1 est un minimum, envisager mieux n'est certainement pas un luxe vu les récents développements autour des collisions sur cet algorithme. Le soucis, c'est que si SHA-1 est supporté par toutes les bibliothèques SSL, ce n'est pas le cas de SHA-2 ou des variantes longues de RIPEMD par exemple. Ensuite, en rendant un peu moins prédictible son mécanisme de génération. Enfin, en renouvelant les CA impactées et, par effet domino, tous les certificats générés par elles en cours de validité. C'est un boulot énorme, aucun doute là-dessus. Mais dans la mesure où personne ne sait si cette attaque n'a pas été réussie précédemment, on ne peut guère compter sur le fait qu'arrêter la génération de certificats faibles suffira à prévenir les conséquences à moyen terme de ce manque de clairvoyance. Côté administrateur de site, si vous dépendez de ces messieurs, il conviendra de demander au plus vite un nouveau certificat signé en SHA-1. Verisign s'est par exemple engagé à vous les renouveler gratuitement.
De mon côté, ça fait un petit moment que j'utilise un plugin pour Firefox appelé Perspectives, qui fournit une gestion des certificats à la SSH, en utilisant une base locale comme mémoire des certificats déjà vus et un réseau de notaires sollicitables au besoin. Le besoin initial pour ce genre d'extension était une meilleure validation des certificats auto-signés et autres CA personnelles. Et c'est pas mal, je vous le recommande, tout du moins vous invite à regarder de quoi il retourne. Ils fournissent aussi le service pour SSH avec un OpenSSH modifié et offrent une interface web.
Une autre mesure côté utilisateur serait de retirer les six CA de la liste de confiance. C'est un peu extrême, en particulier parce que cette mesure va empêcher vos applications d'authentifier les sites qui en dépendent. Pour autant, peut-on vraiment encore faire confiance à ces certificats ? Je vous laisse vous forger votre propre opinion.
Qu'est-ce qu'on doit retenir de tout ça ? Il y aurait pleins de choses à dire sur cette histoire. La réflexion qui me vient à l'esprit et que je crois avoir mentionné dans ces lignes, sinon à des nombreuses reprises oralement, est que la validation des certificats X.509 sur le web repose sur beaucoup d'acteurs commerciaux qui ne me semble pas suffisamment encadrés. Non pas que les acteurs commerciaux soient forcément plus mauvais que les autres, mais parce qu'ils ont des motivations et des impératifs qui rendent tentantes de petites entorses aux bonnes pratiques lorsqu'on ne les a pas à l'œil. Comme ne pas migrer son système de signature de MD5 à SHA-1. Par exemple. Ou à rogner sur les procédures de validation pour les renouvellements de certificat. Souvenez-vous de ce qu'en disait Pierre Vandevenne il y a déjà bien longtemps, à l'échelle d'Internet :
Les sociétés commerciales qui ne sont pas soumises à un contrôle efficace sont fort tentées d'être incompétentes ou malhonnêtes.
On vient de voir un bel exemple d'incompétence. À défaut de malhonnêteté, encore que, voudriez-vous un joli exemple de mauvaise foi ? Pas de problème. Direction le blog de Tim Callan chez Verisign où on nous explique prestement de l'autorité de certification s'est définitivement débarassée de MD5. Mais aussi que ces méchants chercheurs ne les ont pas alerté alors que ce sont de gentils professionnels complètement dans la mouvance white-hat. Affirmation que critique Robert Graham certes violemment, mais avec des arguments on ne peut plus valide. Là où ça laisse perplexe, c'est quand on apprend qu'en fait, Verisign avait bel et bien été mis au courant du contenu de la présentation et de ses implications dès le 23 décembre, par l'intermédiaire de Microsoft, mais il semble que l'information se soit perdue dans les méandres de la hiérarchie. La mauvaise foi s'arrêterait-elle où commence l'incompétence ?...
La question est donc de savoir à qui on peut faire confiance, et pourquoi faire exactement. SSL est basé sur un modèle de confiance qui à certes bien des défauts, mais qui, bien utilisé, peut se révéler très efficace. Dans ce "bien utilisé", il y a en particulier une étape de vérification. Car la confiance ne tombe pas du ciel : elle se mérite. Exactement comme l'explique Richard Thieme pour un tout autre sujet :
Trust, but verify...
Notes
[1] À savoir Alexander Sotirov, Marc Stevens, Jacob Appelbaum, Arjen Lenstra, David Molnar, Dag Arne Osvik et Benne de Weger.
[2] Plus couramment appelées CA, pour Certification Authorities.
[3] Filiale de Verisign depuis le rachat de GeoTrust fin 2006.



I. La révolution des expériences contrôlées
Pour comprendre l’enthousiasme récent des économistes pour les expériences contrôlées, il est nécessaire de faire un (rapide) survol des méthodes utilisées par les économistes dans le passé. Dans les années 1980, la méthode reine est la régression en coupe internationale : on rassemble des données sur 100 pays et on regarde les corrélations entre différentes variables. Par exemple, on constate que le montant de l’aide au développement est négativement associé à la croissance du pays. Il est alors évident que l’on ne peut en tirer aucune conclusion en termes de causalité : l’aide au développement cause–t-elle une faible croissance, ou l’inverse ?
James Heckman, prix Nobel d’économie et grand monsieur de l’économétrie, a inventé (après d’autres) une solution statistique au problème : il suffit de trouver un « instrument », c’est-à-dire une variable qui permette d’expliquer le niveau de l’aide versée mais qui soit indépendante de la croissance. L’instrument ainsi trouvé permettra d’approcher l’effet causal de l’aide sur la croissance : il s’agit de la méthode des variables instrumentales.
Cette méthode a été reprise puis adaptée aux cas des « expériences naturelles ». Celles-ci reposent sur l’idée que si l’on peut identifier deux groupes identiques et si l’un de ces groupes bénéficie de – ou subit – un « traitement » (une politique, un choc économique), il est possible de tirer des conclusions sur l’effet net moyen de ce « traitement » sur différentes variables (le revenu, la probabilité d’emploi, la santé, etc.). Si les conditions sont réalisées on pourra alors parler de causalité.
Toute une école d’économistes s’est lancée dans ces nouvelles méthodes, en particulier à Harvard et au MIT (Orley Ashenfelter, Josh Angrist ou plus récemment Steven Levitt sont des exemples parmi beaucoup d’autres). Les expériences naturelles ont fleuri et avec elles de multiples techniques (double différence, matching, regression dicscontinuity, etc). Avec la prolifération de ce type d’études, la qualité des travaux s’est néanmoins détériorée. Les multiples vérifications, pour s’assurer que les groupes de contrôle et groupes tests ne sont pas touchés par la réforme étudiée, étaient plus rarement mises en pratique. Le stock de « bonnes expériences naturelles » ou de « bons instruments » est vite apparu comme limité. Quelques chercheurs, particulièrement conscients des difficultés qu’il y avait à réaliser ces bonnes expériences naturelles, ne souhaitaient pas en rester là. Si les expériences naturelles étaient rares, ne fallait-il pas créer ce que la « nature » n’avait pas produit et passer à l’expérimentation « contrôlée » ?
L’expérimentation en économie s’est développée dans deux domaines en particulier : l’évaluation des politiques publiques et l’économie du développement. Dans les deux cas, l’évaluation avait pour objectif d’optimiser l’utilisation de ressources rares (l’argent des contribuables ou l’aide au développement) afin de maximiser l’efficacité pour les bénéficiaires.
En économie du développement, les chercheurs qui ont le plus œuvré dans cette direction sont deux brillants économistes du MIT, Esther Duflo et Abhijit Banerjee. Ils ont créé une fondation « Abdul Latif Jameel Poverty Action Lab » dédiée entièrement au financement d’expérimentation de différentes politiques d’aide aux pays en voie de développement. L’objectif était de sortir des contraintes des expériences naturelles (où l’on est dépendant de l’expérience que l’on trouve) afin de se concentrer sur les questions pour lesquelles on cherchait des réponses. Le choix de l’expérimentation repose sur l’avantage considérable du tirage aléatoire (randomization) pour mesurer les effets d’une politique (ou d’une aide spécifique). Les résultats sont précis et robustes. De multiples études ont été réalisées qui nous ont appris beaucoup sur la façon de bien conduire de l’aide au développement (voir cet article récent qui liste les résultats surprenants d’expérimentations récentes). De plus en plus d’ONG calquent leur pratique sur les enseignements de ces études et travaillent avec des chercheurs pour améliorer l’efficacité de leurs actions. A l’opposé de la caricature d’économistes loin de la réalité en train de manipuler de grandes théories, ces chercheurs ouvrent la boite noire de la production des politiques publiques. Par exemple comment améliorer l’éducation dans les pays en voie de développement ? Faut-il embaucher plus de professeurs, payer des livres, subventionner les cantines scolaires ou vérifier la présence des professeurs. Banerjee et Duflo expliquent que les expérimentations ont pu mettre en lumière l’efficacité sensiblement différente des politiques pour obtenir le même niveau d’éducation. L’enthousiasme, légitime, de ces jeunes chercheurs les a amené à considérer l’expérimentation comme l’idéal méthodologique (le « gold standard ») de l’économie empirique mais aussi comme l’espoir d’un renouveau de l’engagement citoyen et la promesse d’un monde meilleur...
II. Les critiques des sceptiques
Ces nouvelles méthodes n’ont pourtant pas convaincu tout le monde. Elles suscitent même de sérieuses controverses parmi les économistes (relatées en partie par The Economist). Récemment, à l’occasion de la publication d’un livre au MIT Press par Abhijit Banerjee, Making Aid Work, puis d’une conférence organisée par le Brookings Institute, le très respecté Angus Deaton (Princeton) et le non moins écouté Dani Rodrik (Harvard) ont chacun fait part de leurs inquiétudes devant le développement de ces méthodes (ou les attentes que l’on peut en avoir). Deaton raille ainsi ces « randomistas » qui ont développé une passion pour les expérimentations et dénonce les expérimentations comme la dernière lubie à la mode. Deux types de critique sont mises en avant.
1. L’éthique en question
Le premier problème de l’expérimentation est un problème éthique. L’identification d’un groupe de contrôle et d’un groupe test suppose que l’on choisit consciemment de ne pas « traiter » tout le monde. Comme le « traitement » est généralement une politique ou de l’aide que l’on juge a priori bénéfique, il est difficile de ne pas voir une injustice à ne pas offrir cette aide à tout le monde. L’argument des chercheurs a été de pointer le fait qu’on ne connaît pas l’efficacité des différentes aides possibles. Les ressources étant rares, chaque ONG est finalement contrainte à faire un choix d’un pays et même d’une petite région où opérer. En testant les différentes aides possibles par expérimentation, les ONG peuvent non seulement lever plus de ressources mais également privilégier les méthodes les plus efficaces, aidant ainsi un nombre bien plus large d’individus.
Mais cette justification apparaît parfois difficile à tenir. Si personne ne réagit fortement lorsque l’on évalue l’aide à l’éducation en comparant l’achat de livres par rapport à l’achat de l’uniforme ou l’effet de la présence des enseignants, lorsqu’on parle de l’effet de traitement médicaux sur les performances scolaires, de légitimes questions doivent être posées. Edward Miguel et Michael Kremer ont ainsi étudié l’effet d’un traitement contre les vers intestinaux sur l’absentéisme à l’école afin de mesurer les effets d’externalité des politiques de santé sur l’accumulation de capital humain. Cet article, qui est par ailleurs un article « phare » de cette école de recherche, a causé des discussions animées sur la justification éthique de telles recherches. Le processus expérimental a consisté à tirer au hasard des enfants kenyans en administrant à seulement la moitié d’entre eux le traitement contre les vers pour mesurer l’effet du traitement sur les performances scolaires (on connaît l’efficacité directe du traitement en terme de santé et le coût du traitement est très faible). Les chercheurs pointent que cette étude a permis de mettre en évidence qu’un traitement qui coûte 30 centimes permet d’obtenir un supplément d’éducation aussi tangible que de couteuses politiques à plus de 6000 $. Au lieu de financer des livres pour chaque enfant, il est possible – pour le même coût – d’être vingt mille fois plus efficace en offrant un traitement contre les vers à tous les enfants africains.
Le résultat de cette étude valait-il le coût éthique de cette expérimentation ? Est-il mieux de pouvoir mesurer cette externalité ou faut-il savoir limiter les champs d’expérimentation ? En d’autres termes, la fin justifie-t-elle les moyens ? Même si l’objectif final est d’aider ces populations, on ne peut s’empêcher de penser que s’il est plus facile de réaliser ces expériences dans les pays en voie de développement c’est aussi parce que dans les pays développés, les citoyens ont leur mot à dire sur l’opportunité de ces études…
2. Les limites méthodologiques
Plus que le problème éthique, ce qui semble le plus agacer les sceptiques, ce sont les prétentions de supériorité méthodologique.
James Heckman rappelle que la validité des expérimentations n’est que conditionnelle. Les résultats ne sont valables que dans le contexte de l’expérimentation (dans le pays, sur l’échantillon traité, selon les conditions macroéconomiques, etc.) . Ainsi, si une expérience met en évidence que l’aide aux chômeurs en Suède pendant une forte période de croissance est positive sur le retour à l’emploi, cela ne permet pas d’en déduire l’effet d’une politique similaire en France pendant une période de récession. Selon les mots de Deaton, le risque est d’amasser des faits et non de la connaissance. Les défenseurs des expérimentations lui rétorque que c’est une raison supplémentaire de faire plus d’expériences et non moins !
Les sceptiques répliquent alors que la multiplication des expérimentations de résout pas le fait qu’elles ne mesurent pas tous les effets. Ainsi, une politique peut être efficace à dose homéopathique (lorsqu’elle n’a pas d’impact sur les coûts ou les marchés du travail) mais peut se révéler complètement inefficace une fois qu’on prend en compte ses impacts macroéconomiques. C’est pourquoi Deaton raille les espoirs mis dans les expérimentations car, selon lui, elles ne peuvent qu’évaluer des petites politiques mais deviennent obsolètes dès que l’aide versée est suffisamment importante pour faire une différence.
L’autre point du débat est l’opposition entre vision micro et macro. Si les méthodes empiriques des macroéconomistes ont été discréditées au profit d’analyses micro plus rigoureuses et plus ciblées, les analyses globales (institutions, ouverture commerciale, etc.) n’en restent pas moins pertinentes pour expliquer le développement économique. Comme Deaton et Rodrik le soulignent, les pays qui se sont développés récemment (et ont sorti de la pauvreté des millions d’individus) ne l’ont pas fait en s’appuyant sur une aide extérieure et encore moins sur des politiques de développement expérimentées au préalable, mais en s’ouvrant au commerce, en garantissant les droits de propriété et en luttant contre la corruption.
Au final, doit-on reprocher à l’expérimentation d’apporter des informations très précises certes mais sur des points somme toute négligeables ?
III. Qu’en conclure?
Ce débat peut laisser songeur. Lorsque l’on compare la défense des expérimentations par Duflo et Banerjee et les critiques qui leur sont faites, on ne peut s’empêcher de penser que tout le monde s’accorde en fait sur deux points essentiels : les expérimentations sont extrêmement utiles et correspondent à un progrès substantiel par rapport aux analyses passées. Mais ce n’est pas la fin de l’histoire pour autant et d’autres méthodes, avec une meilleure compréhension des mécanismes, devront être développées. Une des voies d’avenir serait de parvenir à modéliser les comportements économiques en testant les hypothèses lors d’expériences : si le modèle est robuste à ces tests, il peut être utilisé pour juger d’autres politiques, hors du contexte de l’expérimentation ou pour évaluer des politiques qui ne peuvent pas être soumises à l’expérimentation.
L’opposition micro/macro est aussi stérile. Certes, les grands mouvements macroéconomiques (croissance, commerce) sont probablement plus importants pour la réduction de la pauvreté dans les pays pauvres, mais en rester à un niveau d’analyse macro n’a souvent aucun intérêt pratique : savoir si l’aide en soi est bonne ou pas pour la croissance n’est pas forcément la bonne question à poser au vu de l’hétérogénéité de l’aide possible. Essayer de comprendre quel type d’aide est efficace, ou est contreproductif, est probablement plus important. Pour ce faire, une combinaison d’expérimentations et de modélisation d’effets macroéconomiques sera déterminante.
Il est enfin difficile de reprocher aux partisans des expérimentations le souhait de voir ajouter au mur de la connaissance économique des petites mais solides pierres, quand on compte le nombre de grandes théories qui n’ont pas survécu à leur auteur. La modestie de ces approches est au contraire tout à l’honneur des chercheurs qui les poursuivent. Ceux qui en viennent à professer que les expérimentations sont la seule voie pour sauver le monde n’en ont simplement pas compris la philosophie.
Les plus jeunes d’entre-vous ne s’en souviennent peut-être pas mais il y avait une vie avant l’iPhone, et même avant les smartphones. Á l’époque on appelait ça des PDA (Assistants personnels numériques) et des marques comme Palm ou Psion dominaient le marché. Et il y avait même un terminal chez Apple (le Newton) !
Aujourd’hui (du moins hier) le marché des smartphones est dominé par des acteurs comme RIM avec son Blackberry, Nokia et sa plateforme Symbian et Microsoft avec Windows Mobile et toujours Apple qui tente d’imposer son iPhone dans le monde de l’entreprise.
Après quelques années d’évolution “tranquille”, voilà qu’Apple arrive sur le marché avec son iPhone et bouleverse l’ordre établi. Puis c’est au tour de Google avec son système d’exploitation Android et maintenant c’est au tour de Palm de nous faire un come back spectaculaire avec son Pre (qui éclipse illico l’échec retentissant du Foleo. Plus de détails ici : Palm Pre and webOS in action.
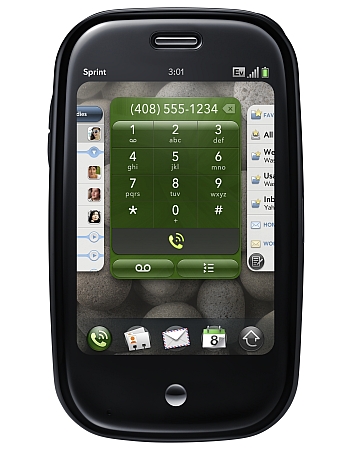
Le tout nouveau Palm Pre
Le moins que l’on puisse dire, c’est que les clients sont largement gagnants dans cette histoire car les interfaces des trois plateformes dominantes n’étaient pas des modèles de convivialité (lire à ce sujet : Memo To RIM, Windows Mobile: Palm Just Kicked Your Butt).
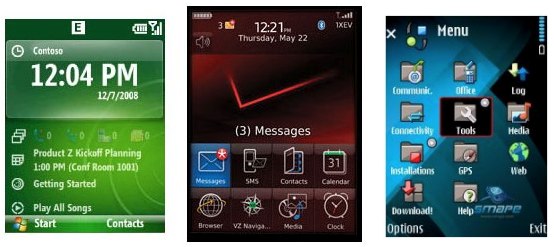
Windows Mobile, Blackberry et Symbian
Les smartphones “nouvelle vague” viennent bousculer les codes avec des interfaces bien plus attrayantes avec une expérience utilisateur nettement plus agréable et un esthétisme qui n’a pas été sacrifié sur l’autel de la productivité (qui ne sont pourtant pas deux notions antagonistes) :

Iphone, Palm Pre et Google G1
Bref, je me réjouis du grand retour de Palm dans la course avec ce terminal tout à fait intéressant qui innove sur plus d’un point :
- Un large écran doublé d’une zone tactile baptisée “Gesture area”) ;
- De très belles cinématiques d’ouvertures et transitions au lancement ou à la fermeture des applications ;
- Un système d’exploitation multi-tâches avec la possibilité de naviguer entre les applications à l’aide d’une interface qui est à mi-chemin entre le coverflow de Mac OS et les “onglets” de Safari mobile ;
- Un système de notifications très efficace ;
- Une messagerie unifiée avec des Buddy lists et des conversations ;
- Un système de synchronisation native entre le Pre et d’autres terminaux au travers du WebOS (qui porte mal son nom) ;
- Un rechargement par induction à l’aide du TouchStone, un socle révolutionnaire (oui mais quid de la synchronisation ?).
Rajoutez à cela un écosystème d’éditeurs tiers qui sommeillaient depuis des années et qui ne demandent qu’à reprendre du service pour échapper à l’emprise d’Apple sur l’iTunes App Store et vous avez un futur hit. Lire à ce sujet la comparatif suivant : Palm Pre vs. iPhone vs. G1.
Sans jouer les prévisionnistes du dimanche, je suis persuadé que 2009 va être une année charnière dans le monde de l’internet mobile car avec 6 concurrents de taille sur le créneau, la bataille va être très dure. Il y a fort à parier que ces 6 poids lourds redoublent d’efforts dans la course à l’innovation et que nous (les consommateurs) en soyons les bénéficiaires directs.
Et le pire dans tout ça, c’est que le sulfureux marché des netbooks va également bouleverser nos habitudes de consommation de l’internet. Mais je prépare un article sur le sujet…
Depuis peu, on trouve de curieuses réponses dans les résultats de recherche de Google, notamment quand on l’interroge sur des dates de naissances ou les liens familiaux. Google répond désormais à la question posé plutôt que de pointer vers des pages contenant éventuellement une réponse. Pour l’instant, cela fonctionne avec l’anglais, et, dans une moindre mesure, avec le Français (c’est nettement moins impressionnant avec le Français, il faut le reconnaître).
Quel est le nom de la femme de Johnny Hallyday ? Quel est la capitale de la France ? Désormais, ces questions posées à Google obtiennent une réponse simple, articulée dans le classique ‘sujet-prédicat-objet’ (le célèbre ‘triplet’ du web sémantique), le tout accompagné de la source justifiant la réponse. Bien sûr, le tout est suivit des traditionnels résultats de recherche propres à Google.
Les informations ne sont pas structurées de la sorte sur le web, en particulier dans les sources qu’utilise Google pour justifier ses réponses, celui-ci semble analyser des données semi structurées, voir pas structurées du tout. C’est une fonctionnalité qui a coûté 100 millions de dollars à Microsoft et qui à justifié le rachat l’an dernier de Powerset, qui, rappelons-le, n’est capable de tels résultats que sur un corpus réduit (Wikipedia en l’occurrence), en en aucun cas sur l’ensemble du web (ou en tout cas sur une large palette de sources) comme semble le faire Google.
Il est clair que Google expérimente de tels analyses sémantiques sur des données non structurés depuis déjà pas mal de temps, mais à notre connaissance, c’est la première fois que cette capacité est ainsi exposée au public. (un programme de Google appelé “Direct Answers” explore l’analyse sémantique de données non structurés depuis quelques années, mais il n’était pas accessible au public).
La fonctionnalité n’est pas accessible en permanence et sur tous les territoires, il nous a fallu, en France, passer par un proxy anonyme américain pour y avoir accès. Il n’est par ailleurs pas évident que cette fonctionnalité soit accessible à des tiers, mais cela ne semble pas impossible à faire, même si - et c’est fort dommage - les données fournies par Google ne sont pas structurées en RDF au sein du HTML des résultats de Google.
Google structure-t-il les données non structurées ?
Bruno Haid, de la startup sémantique Australienne System One qui nous a fourni cette information, l’a commenté de la façon suivante :
“Ce qui est intéressant c’est que, bien que les données concernant la mère de Justin Timberlake, parmi d’autres, soient issues de http://www.celebritywonder.com/html/justintimberlake.html, il n’y a aucune donnée structurée de façon sémantique qui permet d’identifier Lynne comme étant la mère de Britney Spears. Donc soit Google utilise une source d’information structurée qu’il ne révèle pas dans ses résultats, soit ils arrivent réellement à extraire cette information du texte non structuré qu’ils affichent comme source (http://ububu.com/BritneySpears.html). Si c’est la cas, c’est énorme.
Toute la question est là. Conclure que Google fait de l’analyse sémantique simplement parce qu’ils affichent des résultats sous la forme “sujet-prédicat-objet” serait aller un peu vite en besogne, mais si cette structure résulte d’une analyse automatique de la part de Google, et qu’ils s’avéraient capable de structurer sémantiquement des données non structurées, qui n’existent nulle part sous une forme structurée sémantiquement, alors on pourrait conclure que Google est capable de faire cela. Et cela semble bien être le cas.
Pourquoi est-ce important ?
Comme nous avons désormais coutume de le dire au sujet du web sémantique, une fois que la machine sera capable d’extraire du savoir d’une page web à notre place, une large partie du travail des ‘knowledge worker’ sera déjà réalisé par la machine, donnant aux humains la possibilité d’aller bien plus loin encore, les gain de productivité de tous ceux qui travaillent quotidiennement avec comme matière première de l’information seraient phénoménaux.
Certes, pour l’instant, les réponses ne sont pas toujours très pertinentes, et tout cela n’est qu’un début. Quand on demande la date de naissance de Jésus, le résultat est plutôt surprenant, et la date de naissance de Laeticia Hallyday, à en croire Google (voir copie d’écran au début de l’article), mènerait notre Johnny national tout droit en prison si elle était exacte. Yahoo, de son coté, a exposé une vision bien plus claire sur ses intentions face au web sémantique, mais malgré tout, Google semble faire quelque chose que personne jusqu’ici n’a réussi a faire. Encore une fois, la création de valeur qu’apporterait une telle technologie, une fois mature, est tout simplement phénoménale.
A lire sur le même thème :
- Qui contrôlera vos données dans le Web 3.0 ?
- Clips muets sur Youtube : règlement de comptes au Midem
- Ce que Google donne, Google peut le reprendre ou la fermeture de Google Video, Notebook, Catalog Search, Jaiku et Dodgeball
- Google répond à la presse
- Le prochain livre de Jeff Jarvis auto-censuré en France